Die Arbeit von Data Scientist ist jedoch an Daten gebunden, und einer der wichtigsten und zeitaufwändigsten Momente ist die Verarbeitung der Daten, bevor sie an das neuronale Netzwerk gesendet oder auf eine bestimmte Weise analysiert werden.
In diesem Artikel beschreibt unser Team, wie Sie Daten mit schrittweisen Anweisungen und Code schnell und einfach verarbeiten können. Wir haben versucht, den Code so flexibel zu gestalten, dass er auf verschiedene Datensätze angewendet werden kann.
Viele Fachleute finden in diesem Artikel möglicherweise nichts Außergewöhnliches, aber Anfänger können etwas Neues lernen, und jeder, der lange davon geträumt hat, ein separates Notizbuch für eine schnelle und strukturierte Datenverarbeitung zu erstellen, kann den Code kopieren und für sich selbst formatieren oder einen vorgefertigten herunterladen. Notizbuch von Github.
Wir haben einen Datensatz. Was macht man als nächstes?
Der Standard: Sie müssen verstehen, womit wir es zu tun haben, das große Ganze. Wir werden dafür Pandas verwenden, um einfach verschiedene Datentypen zu definieren.
import pandas as pd # pandas
import numpy as np # numpy
df = pd.read_csv("AB_NYC_2019.csv") # df
df.head(3) # 3 , , 
df.info() # 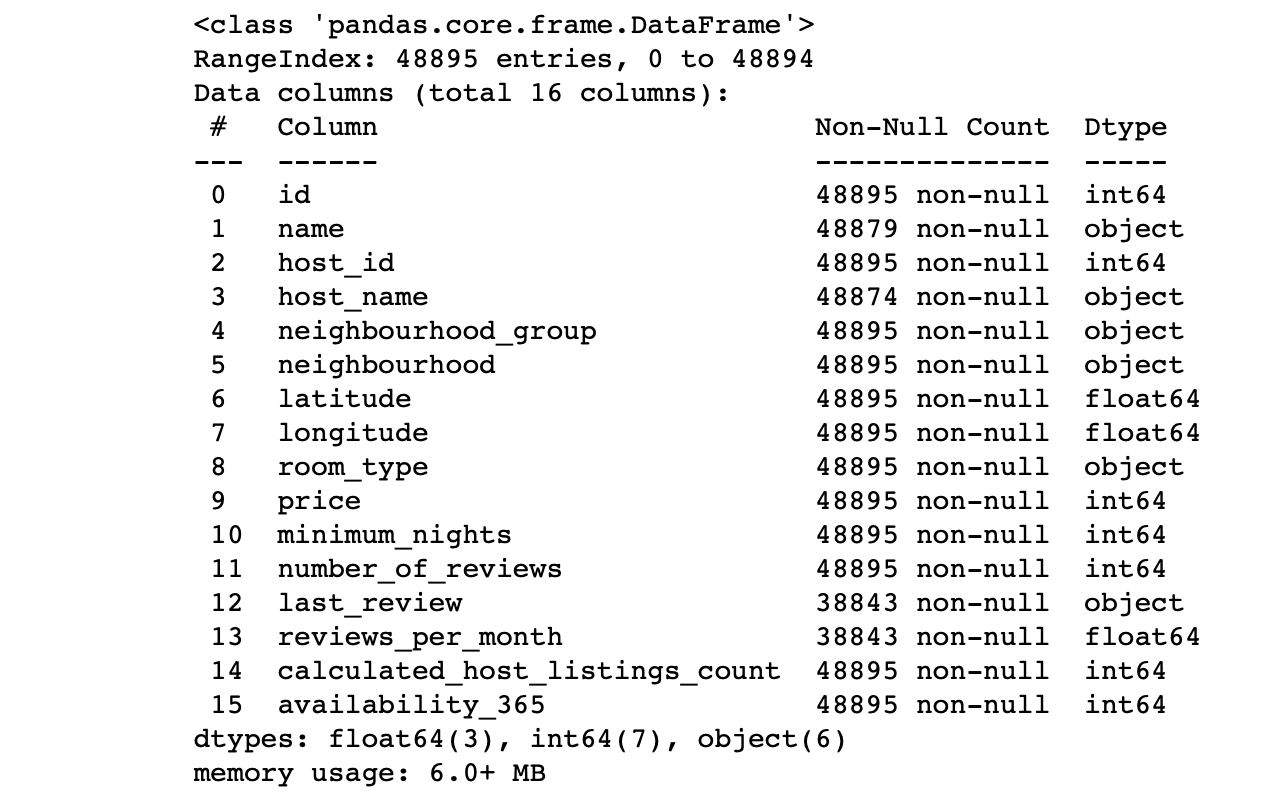
Wir betrachten die Werte der Spalten:
- Entspricht die Anzahl der Zeilen in jeder Spalte der Gesamtzahl der Zeilen?
- Was ist die Essenz der Daten in jeder Spalte?
- Für welche Spalte soll das Ziel Vorhersagen treffen?
Mit den Antworten auf diese Fragen können Sie den Datensatz analysieren und grob einen Plan für die nächsten Schritte erstellen.
Für einen genaueren Blick auf die Werte in jeder Spalte können wir auch die Funktion pandas description () verwenden. Der Nachteil dieser Funktion besteht jedoch darin, dass sie keine Informationen zu Spalten mit Zeichenfolgenwerten bereitstellt. Wir werden uns später darum kümmern.
df.describe()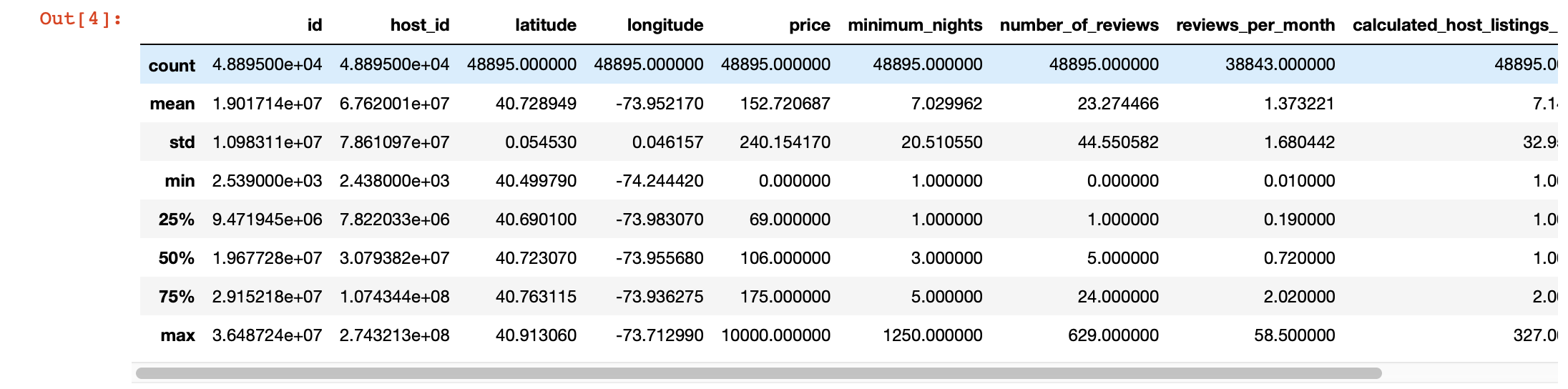
Magische Visualisierung
Schauen wir uns an, wo wir überhaupt keine Werte haben:
import seaborn as sns
sns.heatmap(df.isnull(),yticklabels=False,cbar=False,cmap='viridis')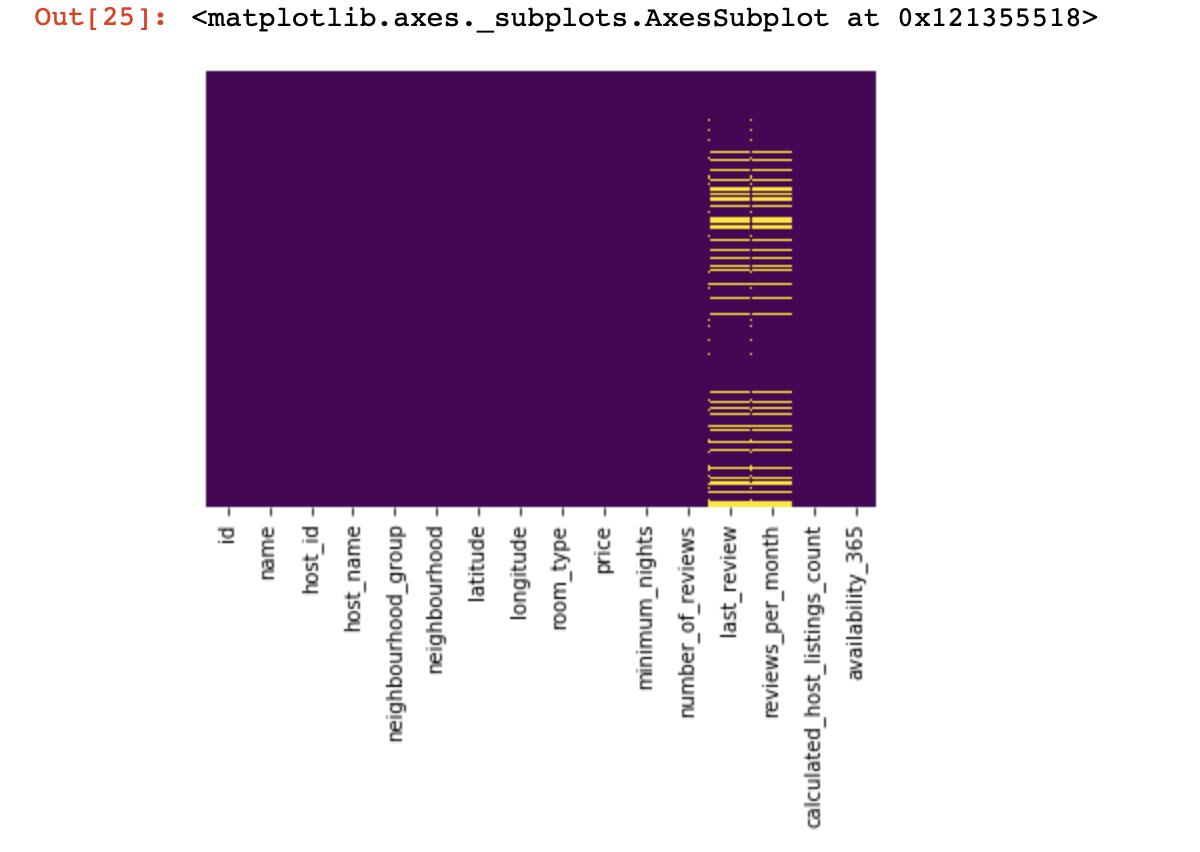
Es war ein kleiner Blick von oben, jetzt kommen wir zu interessanteren Dingen.
Versuchen wir, Spalten zu finden und wenn möglich zu löschen, die nur einen Wert in allen Zeilen haben (sie haben keinerlei Auswirkungen auf das Ergebnis):
df = df[[c for c
in list(df)
if len(df[c].unique()) > 1]] # , , Jetzt schützen wir uns und den Erfolg unseres Projekts vor doppelten Zeilen (Zeilen, die dieselben Informationen in derselben Reihenfolge wie eine der vorhandenen Zeilen enthalten):
df.drop_duplicates(inplace=True) # , .
# .Wir teilen den Datensatz in zwei Teile: einen mit qualitativen Werten und einen mit quantitativen Werten
Hier müssen wir eine kleine Klarstellung machen: Wenn die Zeilen mit fehlenden Daten in qualitativen und quantitativen Daten nicht stark miteinander korrelieren, muss entschieden werden, was wir opfern - alle Zeilen mit fehlenden Daten, nur ein Teil davon oder bestimmte Spalten. Wenn die Linien verwandt sind, haben wir jedes Recht, den Datensatz in zwei Teile zu teilen. Andernfalls müssen Sie sich zuerst mit den Zeilen befassen, die die fehlenden Daten nicht qualitativ und quantitativ korrelieren, und erst dann den Datensatz in zwei Teile teilen.
df_numerical = df.select_dtypes(include = [np.number])
df_categorical = df.select_dtypes(exclude = [np.number])Wir tun dies, um uns die Verarbeitung dieser beiden unterschiedlichen Datentypen zu erleichtern. Später werden wir verstehen, wie sehr dies unser Leben vereinfacht.
Wir arbeiten mit quantitativen Daten
Als erstes sollten wir feststellen, ob die quantitativen Daten "Spionagespalten" enthalten. Wir nennen diese Spalten dies, weil sie sich als quantitative Daten ausgeben und selbst als qualitative Daten fungieren.
Wie definieren wir sie? Natürlich hängt alles von der Art der Daten ab, die Sie analysieren, aber im Allgemeinen können solche Spalten nur wenige eindeutige Daten enthalten (im Bereich von 3 bis 10 eindeutigen Werten).
print(df_numerical.nunique())Nachdem wir die Spionagespalten definiert haben, werden wir sie von quantitativen zu qualitativen Daten verschieben:
spy_columns = df_numerical[['1', '2', '3']]# - dataframe
df_numerical.drop(labels=['1', '2', '3'], axis=1, inplace = True)#
df_categorical.insert(1, '1', spy_columns['1']) # -
df_categorical.insert(1, '2', spy_columns['2']) # -
df_categorical.insert(1, '3', spy_columns['3']) # - Schließlich haben wir quantitative von qualitativen Daten vollständig getrennt und jetzt können Sie richtig damit arbeiten. Das erste ist zu verstehen, wo wir leere Werte haben (NaN, und in einigen Fällen wird 0 als leere Werte genommen).
for i in df_numerical.columns:
print(i, df[i][df[i]==0].count())In diesem Stadium ist es wichtig zu verstehen, in welchen Spalten die Nullen fehlende Werte bedeuten können: hängt dies damit zusammen, wie die Daten gesammelt wurden? Oder könnte es sich um Datenwerte handeln? Diese Fragen müssen von Fall zu Fall beantwortet werden.
Wenn wir also dennoch entscheiden, dass wir möglicherweise keine Daten mit Nullen haben, sollten wir die Nullen durch NaN ersetzen, damit es später einfacher ist, mit diesen verlorenen Daten zu arbeiten:
df_numerical[[" 1", " 2"]] = df_numerical[[" 1", " 2"]].replace(0, nan)Nun wollen wir sehen, wo wir fehlende Daten haben:
sns.heatmap(df_numerical.isnull(),yticklabels=False,cbar=False,cmap='viridis') # df_numerical.info()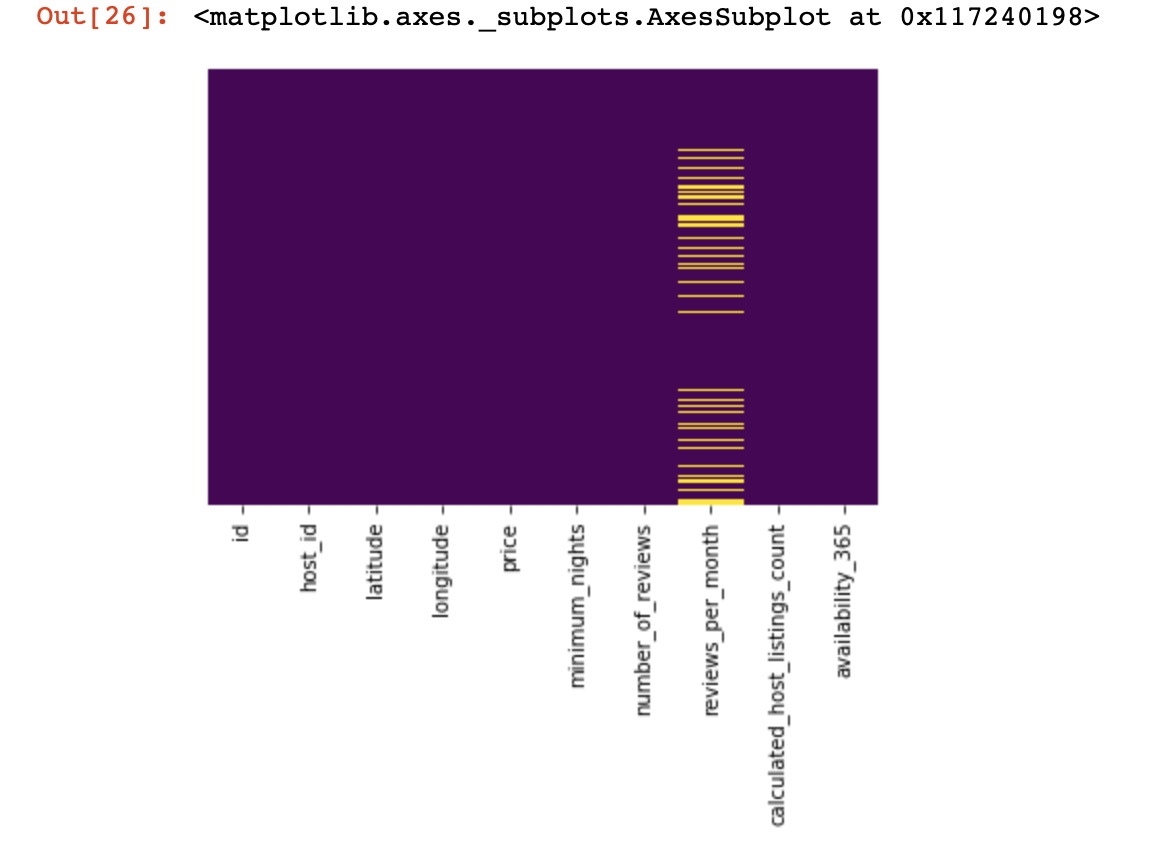
Hier sollten die fehlenden Werte in den Spalten gelb markiert werden. Und der Spaß beginnt jetzt - wie verhält man sich mit diesen Werten? Zeilen mit diesen Werten oder Spalten löschen? Oder diese leeren Werte mit anderen füllen?
Hier ist ein grobes Diagramm, das Ihnen bei der Entscheidung helfen kann, was Sie grundsätzlich mit leeren Werten tun können:
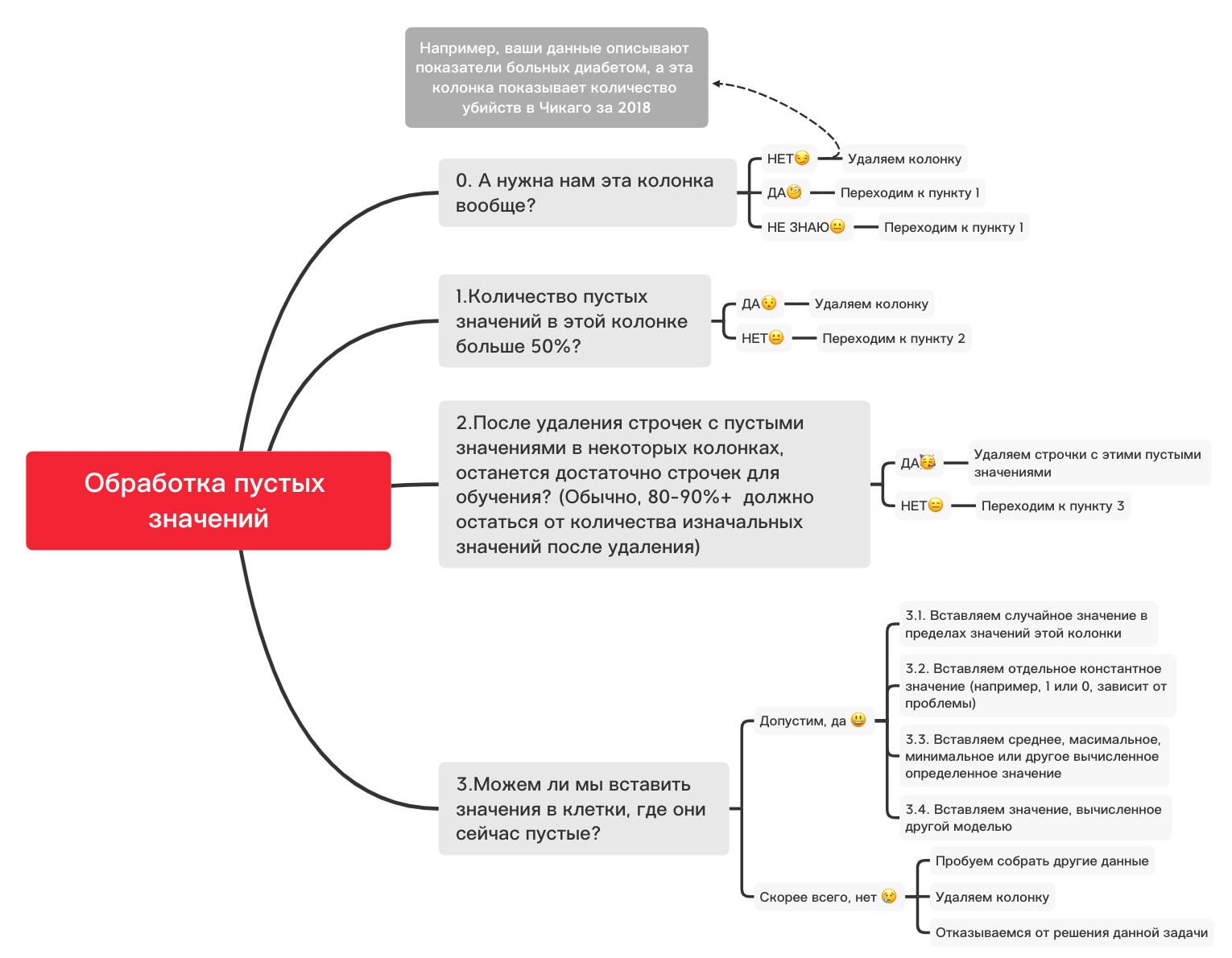
0. Entfernen Sie unnötige Spalten
df_numerical.drop(labels=["1","2"], axis=1, inplace=True)1. Gibt es in dieser Spalte mehr als 50% Leerwerte?
print(df_numerical.isnull().sum() / df_numerical.shape[0] * 100)df_numerical.drop(labels=["1","2"], axis=1, inplace=True)#, - 50 2. Löschen Sie Zeilen mit leeren Werten
df_numerical.dropna(inplace=True)# , 3.1. Fügen Sie einen zufälligen Wert ein
import random # random
df_numerical[""].fillna(lambda x: random.choice(df[df[column] != np.nan][""]), inplace=True) # 3.2. Konstantenwert einfügen
from sklearn.impute import SimpleImputer # SimpleImputer,
imputer = SimpleImputer(strategy='constant', fill_value="< >") # SimpleImputer
df_numerical[["_1",'_2','_3']] = imputer.fit_transform(df_numerical[['1', '2', '3']]) #
df_numerical.drop(labels = ["1","2","3"], axis = 1, inplace = True) # 3.3. Geben Sie den Durchschnitt oder den häufigsten Wert ein
from sklearn.impute import SimpleImputer # SimpleImputer,
imputer = SimpleImputer(strategy='mean', missing_values = np.nan) # mean most_frequent
df_numerical[["_1",'_2','_3']] = imputer.fit_transform(df_numerical[['1', '2', '3']]) #
df_numerical.drop(labels = ["1","2","3"], axis = 1, inplace = True) # 3.4. Einfügen eines von einem anderen Modell
berechneten Werts Manchmal können Werte mithilfe von Regressionsmodellen unter Verwendung von Modellen aus der sklearn-Bibliothek oder anderen ähnlichen Bibliotheken berechnet werden. Unser Team wird einen separaten Artikel darüber verfassen, wie dies in naher Zukunft geschehen kann.
Während die Erzählung über quantitative Daten unterbrochen wird, gibt es viele andere Nuancen, wie die Datenvorbereitung und -vorverarbeitung für verschiedene Aufgaben besser durchgeführt werden kann, und grundlegende Dinge für quantitative Daten wurden in diesem Artikel berücksichtigt, und jetzt ist es an der Zeit, zu qualitativen Daten zurückzukehren. was wir ein paar Schritte zurück von quantitativen getrennt haben. Sie können dieses Notizbuch nach Belieben ändern und für verschiedene Aufgaben anpassen, sodass die Datenvorverarbeitung sehr schnell vonstatten geht!
Qualitative Daten
Grundsätzlich wird für Qualitätsdaten die One-Hot-Codierungsmethode verwendet, um sie von einer Zeichenfolge (oder einem Objekt) zu einer Zahl zu formatieren. Bevor wir zu diesem Punkt übergehen, verwenden wir das obige Diagramm und den obigen Code, um mit leeren Werten umzugehen.
df_categorical.nunique()sns.heatmap(df_categorical.isnull(),yticklabels=False,cbar=False,cmap='viridis')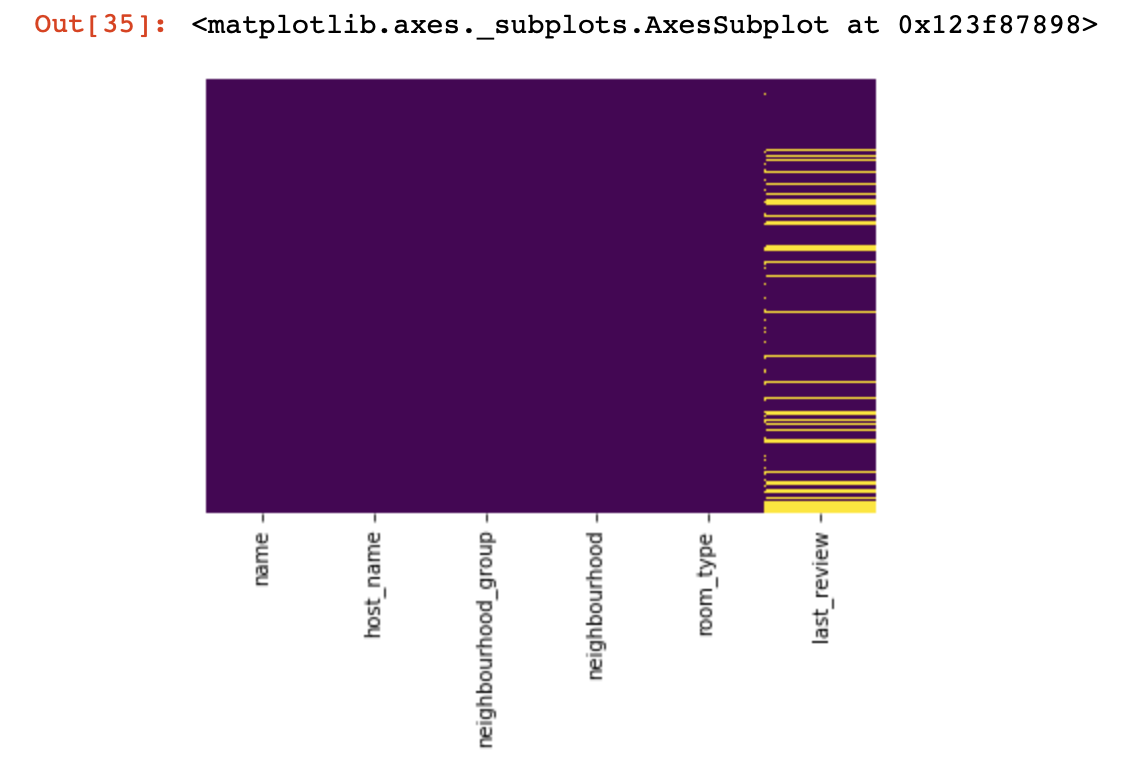
0. Entfernen unnötiger Spalten
df_categorical.drop(labels=["1","2"], axis=1, inplace=True)1. Gibt es in dieser Spalte mehr als 50% Leerwerte?
print(df_categorical.isnull().sum() / df_numerical.shape[0] * 100)df_categorical.drop(labels=["1","2"], axis=1, inplace=True) #, -
# 50% 2. Löschen Sie Zeilen mit leeren Werten
df_categorical.dropna(inplace=True)# ,
# 3.1. Fügen Sie einen zufälligen Wert ein
import random
df_categorical[""].fillna(lambda x: random.choice(df[df[column] != np.nan][""]), inplace=True)3.2. Konstantenwert einfügen
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy='constant', fill_value="< >")
df_categorical[["_1",'_2','_3']] = imputer.fit_transform(df_categorical[['1', '2', '3']])
df_categorical.drop(labels = ["1","2","3"], axis = 1, inplace = True)Schließlich haben wir uns mit leeren Werten in Qualitätsdaten befasst. Jetzt ist es an der Zeit, die Werte, die Sie in Ihrer Datenbank haben, einmalig zu codieren. Diese Methode wird sehr oft verwendet, damit Ihr Algorithmus mit guten Daten trainieren kann.
def encode_and_bind(original_dataframe, feature_to_encode):
dummies = pd.get_dummies(original_dataframe[[feature_to_encode]])
res = pd.concat([original_dataframe, dummies], axis=1)
res = res.drop([feature_to_encode], axis=1)
return(res)features_to_encode = ["1","2","3"]
for feature in features_to_encode:
df_categorical = encode_and_bind(df_categorical, feature))Endlich haben wir die Verarbeitung qualitativer und quantitativer Daten getrennt abgeschlossen - es ist Zeit, sie wieder zu kombinieren
new_df = pd.concat([df_numerical,df_categorical], axis=1)Nachdem wir die Datensätze zu einem zusammengeführt haben, können wir am Ende die Datentransformation mit MinMaxScaler aus der sklearn-Bibliothek verwenden. Dadurch werden unsere Werte zwischen 0 und 1 liegen, was beim zukünftigen Training des Modells hilfreich sein wird.
from sklearn.preprocessing import MinMaxScaler
min_max_scaler = MinMaxScaler()
new_df = min_max_scaler.fit_transform(new_df)Diese Daten sind jetzt für alles bereit - für neuronale Netze, Standard-ML-Algorithmen und so weiter!
In diesem Artikel haben wir die Arbeit mit zeitreihenbezogenen Daten nicht berücksichtigt, da Sie für solche Daten je nach Aufgabe leicht unterschiedliche Verarbeitungstechniken verwenden sollten. In Zukunft wird unser Team diesem Thema einen separaten Artikel widmen, und wir hoffen, dass es in der Lage sein wird, etwas Interessantes, Neues und Nützliches in Ihr Leben zu bringen, wie diesen.