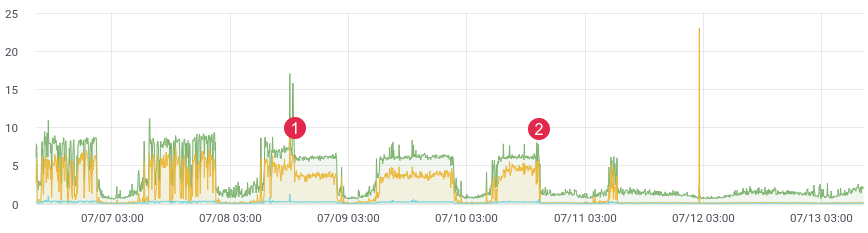
ca. Latenz zeit.
Wahrscheinlich steht jeder vor der Aufgabe, Code in der Produktion zu profilieren. Facebooks xhprof macht das gut. Sie profilieren beispielsweise 1/1000 Anfragen und sehen das Bild im Moment. Nach jeder Veröffentlichung läuft das Produkt und sagt: "Es war vor der Veröffentlichung besser und schneller." Sie haben keine historischen Daten und können nichts beweisen. Was wäre, wenn du könntest?
Vor nicht allzu langer Zeit haben wir einen problematischen Teil des Codes neu geschrieben und einen starken Leistungsgewinn erwartet. Wir haben Unit-Tests geschrieben, Lasttests durchgeführt, aber wie verhält sich der Code unter Live-Last? Schließlich wissen wir, dass beim Lasttest nicht immer echte Daten angezeigt werden. Nach der Bereitstellung müssen Sie schnell Feedback von Ihrem Code erhalten. Wenn Sie Daten sammeln, benötigen Sie nach der Veröffentlichung nur 10 bis 15 Minuten, um die Situation in der Kampfumgebung zu verstehen.
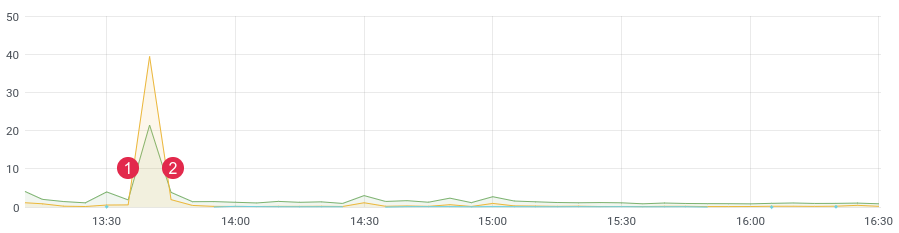
ca. Latenz zeit. (1) Bereitstellen, (2) Zurücksetzen
Stapel
Für unsere Aufgabe haben wir eine spaltenweise ClickHouse-Datenbank (abgekürzt kx) verwendet. Geschwindigkeit, lineare Skalierbarkeit, Datenkomprimierung und kein Deadlock waren die Hauptgründe für diese Wahl. Jetzt ist es eine der Hauptbasen im Projekt.
In der ersten Version haben wir Nachrichten in die Warteschlange geschrieben und bereits von Verbrauchern an ClickHouse geschrieben. Die Verzögerung erreichte 3-4 Stunden (ja, ClickHouse fügt nur langsam nacheinander einAufzeichnungen). Die Zeit verging und es war notwendig, etwas zu ändern. Es hatte keinen Sinn, auf Warnungen mit einer solchen Verzögerung zu reagieren. Dann haben wir einen Crown-Befehl geschrieben, der die erforderliche Anzahl von Nachrichten aus der Warteschlange ausgewählt und einen Stapel an die Datenbank gesendet und diese dann in der Warteschlange als verarbeitet markiert hat. In den ersten paar Monaten war alles in Ordnung, bis auch hier Probleme anfingen. Es gab zu viele Ereignisse, Duplikate von Daten wurden in der Datenbank angezeigt, Warteschlangen wurden nicht für den beabsichtigten Zweck verwendet (sie wurden zu einer Datenbank), und der Befehl Crown konnte das Schreiben in ClickHouse nicht mehr bewältigen. Während dieser Zeit wurden dem Projekt ein paar Dutzend weitere Tabellen hinzugefügt, die in Stapeln in kx geschrieben werden mussten. Die Verarbeitungsgeschwindigkeit ist gesunken. Die Lösung war so einfach und schnell wie möglich. Dies veranlasste uns, Code mit Listen in Redis zu schreiben. Die Idee ist folgende: Wir schreiben Nachrichten an das Ende der Liste,Mit dem Befehl Krone bilden wir ein Paket und senden es an die Warteschlange. Dann analysieren die Verbraucher die Warteschlange und schreiben eine Reihe von Nachrichten in kx.
Wir haben : ClickHouse, Redis und eine Warteschlange (any - rabbitmq, kafka, beanstalkd ...)
Redis und Listen
Bis zu einer bestimmten Zeit wurde Redis als Cache verwendet, aber das ändert sich. Die Basis hat eine enorme Funktionalität und für unsere Aufgabe werden nur 3 Befehle benötigt : rpush , lrange und ltrim .
Wir werden Daten mit dem Befehl rpush an das Ende der Liste schreiben. Lesen Sie im Befehl Crown Daten mit lrange und senden Sie sie an die Warteschlange. Wenn es uns gelungen ist, an die Warteschlange zu senden, müssen Sie die ausgewählten Daten mit ltrim löschen.
Von der Theorie zur Praxis. Lassen Sie uns eine einfache Liste erstellen.

Wir haben eine Liste mit drei Nachrichten, fügen wir noch etwas hinzu ...
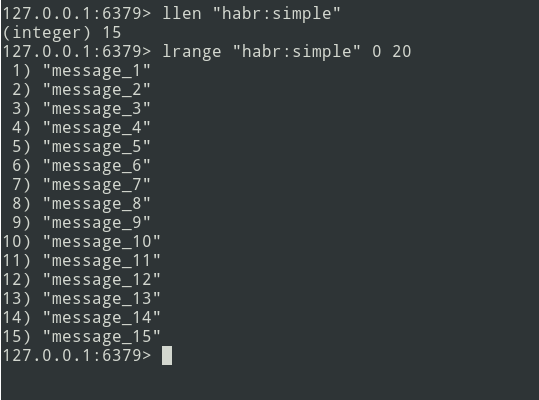
Neue Nachrichten werden am Ende der Liste hinzugefügt. Wählen Sie mit dem Befehl lrange den Stapel aus (lassen Sie ihn = 5 Nachrichten sein).
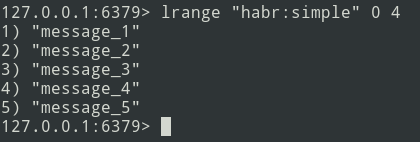
Als nächstes senden wir das Paket an die Warteschlange. Jetzt müssen Sie dieses Bundle aus Redis entfernen, um es nicht erneut zu senden.
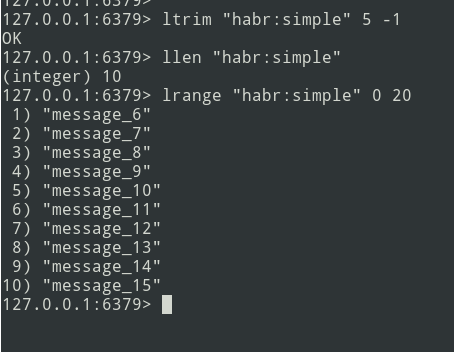
Es gibt einen Algorithmus. Kommen wir zur Implementierung.
Implementierung
Beginnen wir mit der ClickHouse-Tabelle. Ich habe mich nicht allzu sehr darum gekümmert und alles im String- Typ definiert .
create table profile_logs
(
hostname String, // ,
project String, //
version String, //
userId Nullable(String),
sessionId Nullable(String),
requestId String, //
requestIp String, // ip
eventName String, //
target String, // URL
latency Float32, // (latency=endTime - beginTime)
memoryPeak Int32,
date Date,
created DateTime
)
engine = MergeTree(date, (date, project, eventName), 8192);Die Veranstaltung wird wie folgt aussehen:
{
"hostname": "debian-fsn1-2",
"project": "habr",
"version": "7.19.1",
"userId": null,
"sessionId": "Vv6ahLm0ZMrpOIMCZeJKEU0CTukTGM3bz0XVrM70",
"requestId": "9c73b19b973ca460",
"requestIp": "46.229.168.146",
"eventName": "app:init",
"target": "/",
"latency": 0.01384348869323730,
"memoryPeak": 2097152,
"date": "2020-07-13",
"created": "2020-07-13 13:59:02"
}Die Struktur ist definiert. Zur Berechnung der Latenz benötigen wir einen Zeitraum. Wir bestimmen mithilfe der Mikrozeitfunktion :
$beginTime = microtime(true);
//
$latency = microtime(true) - $beginTime;Um die Implementierung zu vereinfachen, verwenden wir das Laravel-Framework und die Laravel-Entry- Bibliothek . Fügen Sie ein Modell hinzu (profile_logs-Tabelle):
class ProfileLog extends \Bavix\Entry\Models\Entry
{
protected $fillable = [
'hostname',
'project',
'version',
'userId',
'sessionId',
'requestId',
'requestIp',
'eventName',
'target',
'latency',
'memoryPeak',
'date',
'created',
];
protected $casts = [
'date' => 'date:Y-m-d',
'created' => 'datetime:Y-m-d H:i:s',
];
}Schreiben wir eine Tick- Methode (ich habe einen ProfileLogService erstellt ), die Nachrichten an Redis schreibt. Wir erhalten die aktuelle Zeit (unsere beginTime) und schreiben sie in die Variable $ currentTime:
$currentTime = \microtime(true);Wenn der Tick für ein Ereignis zum ersten Mal aufgerufen wird, schreiben Sie ihn in das Tick-Array und beenden Sie die Methode:
if (empty($this->ticks[$eventName])) {
$this->ticks[$eventName] = $currentTime;
return;
}Wenn das Häkchen erneut aufgerufen wird, schreiben wir die Nachricht mit der rpush-Methode an Redis:
$tickTime = $this->ticks[$eventName];
unset($this->ticks[$eventName]);
Redis::rpush('events:profile_logs', \json_encode([
'hostname' => \gethostname(),
'project' => 'habr',
'version' => \app()->version(),
'userId' => Auth::id(),
'sessionId' => \session()->getId(),
'requestId' => \bin2hex(\random_bytes(8)),
'requestIp' => \request()->getClientIp(),
'eventName' => $eventName,
'target' => \request()->getRequestUri(),
'latency' => $currentTime - $tickTime,
'memoryPeak' => \memory_get_usage(true),
'date' => $tickTime,
'created' => $tickTime,
]));Die Variable $ this-> ticks ist nicht statisch. Sie müssen den Dienst als Singleton registrieren.
$this->app->singleton(ProfileLogService::class);Die Stapelgröße ( $ batchSize ) ist konfigurierbar. Es wird empfohlen, einen kleinen Wert anzugeben (z. B. 10.000 Elemente). Wenn Probleme auftreten (z. B. ist ClickHouse nicht verfügbar), wird die Warteschlange fehlgeschlagen, und Sie müssen die Daten debuggen.
Schreiben wir einen Kronenbefehl:
$batchSize = 10000;
$key = 'events:profile_logs'
do {
$bulkData = Redis::lrange($key, 0, \max($batchSize - 1, 0));
$count = \count($bulkData);
if ($count) {
// json, decode
foreach ($bulkData as $itemKey => $itemValue) {
$bulkData[$itemKey] = \json_decode($itemValue, true);
}
// ch
\dispatch(new BulkWriter($bulkData));
// redis
Redis::ltrim($key, $count, -1);
}
} while ($count >= $batchSize);Sie können sofort Daten in ClickHouse schreiben, aber das Problem liegt in der Tatsache, dass kronor im Single-Threaded-Modus arbeitet. Daher gehen wir den anderen Weg - mit dem Befehl bilden wir Pakete und senden sie an die Warteschlange für die nachfolgende Multithread-Aufzeichnung in ClickHouse. Die Anzahl der Verbraucher kann reguliert werden - dies beschleunigt das Senden von Nachrichten.
Fahren wir mit dem Schreiben eines Verbrauchers fort:
class BulkWriter implements ShouldQueue
{
use Dispatchable, InteractsWithQueue, Queueable, SerializesModels;
protected $bulkData;
public function __construct(array $bulkData)
{
$this->bulkData = $bulkData;
}
public function handle(): void
{
ProfileLog::insert($this->bulkData);
}
}
}So werden die Bildung von Paketen, das Senden an die Warteschlange und der Verbraucher entwickelt - Sie können mit der Profilerstellung beginnen:
app(ProfileLogService::class)->tick('post::paginate');
$posts = Post::query()->paginate();
$response = view('posts', \compact('posts'));
app(ProfileLogService::class)->tick('post::paginate');
return $response;Wenn alles richtig gemacht wurde, sollten sich die Daten in Redis befinden. Wir werden den Crown-Befehl verwirren und die Packs an die Warteschlange senden, und der Verbraucher wird sie in die Datenbank einfügen.
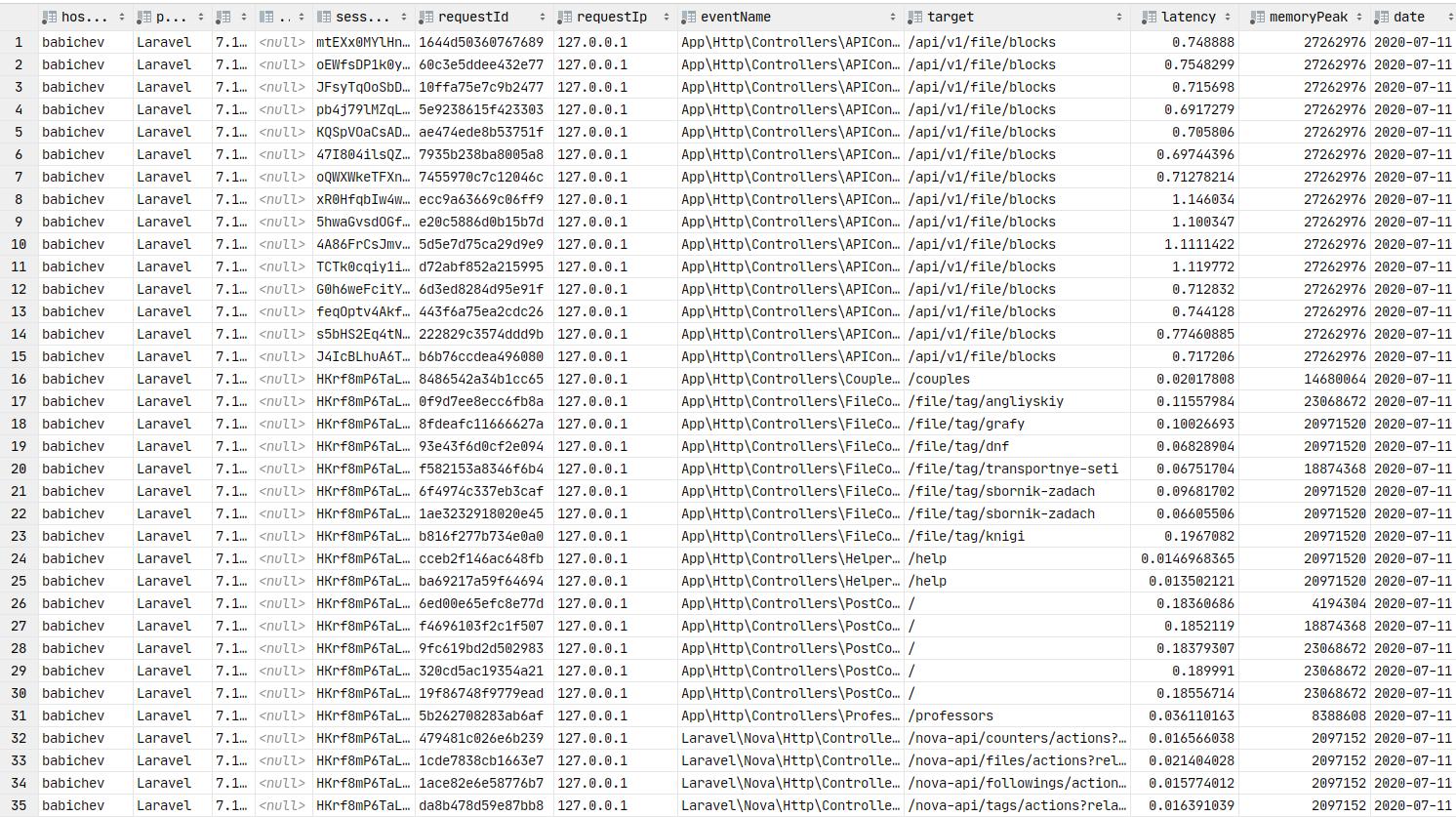
Daten in der Datenbank. Sie können Diagramme erstellen.
Grafana
Kommen wir nun zur grafischen Darstellung der Daten, die ein Schlüsselelement dieses Artikels ist. Sie müssen grafana installieren . Lassen Sie uns den Installationsprozess für debain-ähnliche Assemblys überspringen. Sie können den Link zur Dokumentation verwenden . Normalerweise läuft der Installationsschritt darauf hinaus, grafana zu installieren .
Unter ArchLinux sieht die Installation folgendermaßen aus:
yaourt -S grafana
sudo systemctl start grafanaDer Dienst wurde gestartet. URL: http: // localhost: 3000
Jetzt müssen Sie das ClickHouse-Datenquellen-Plugin installieren :
sudo grafana-cli plugins install vertamedia-clickhouse-datasourceWenn Sie grafana 7+ installiert haben, funktioniert ClickHouse nicht. Sie müssen Änderungen an der Konfiguration vornehmen:
sudo vi /etc/grafana.iniLassen Sie uns die Zeile finden:
;allow_loading_unsigned_plugins =Ersetzen wir es durch dieses:
allow_loading_unsigned_plugins=vertamedia-clickhouse-datasourceSpeichern und starten Sie den Dienst neu:
sudo systemctl restart grafanaErledigt. Jetzt können wir nach Grafana gehen .
Login: admin / Passwort: admin standardmäßig.

Klicken Sie nach erfolgreicher Autorisierung auf das Zahnrad. Wählen Sie im sich öffnenden Popup-Fenster Datenquellen aus und fügen Sie eine Verbindung zu ClickHouse hinzu.
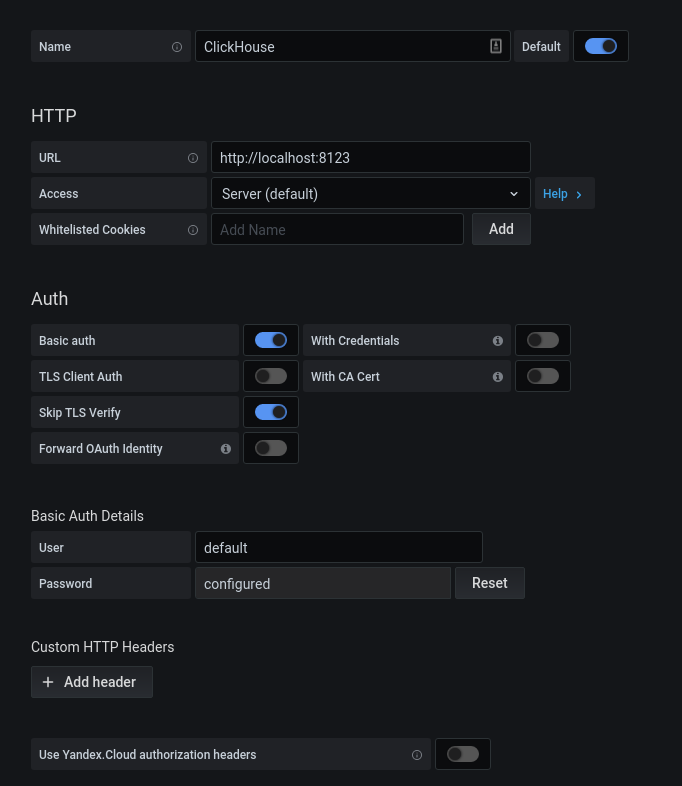
Wir füllen die Konfiguration kx aus. Klicken Sie auf die Schaltfläche "Speichern & Testen". Wir erhalten eine Nachricht über eine erfolgreiche Verbindung. Fügen
wir nun ein neues Dashboard hinzu:
Fügen Sie ein Bedienfeld hinzu:

Wählen Sie die Basis und die entsprechenden Spalten für die Arbeit mit Datumsangaben aus:
Fahren
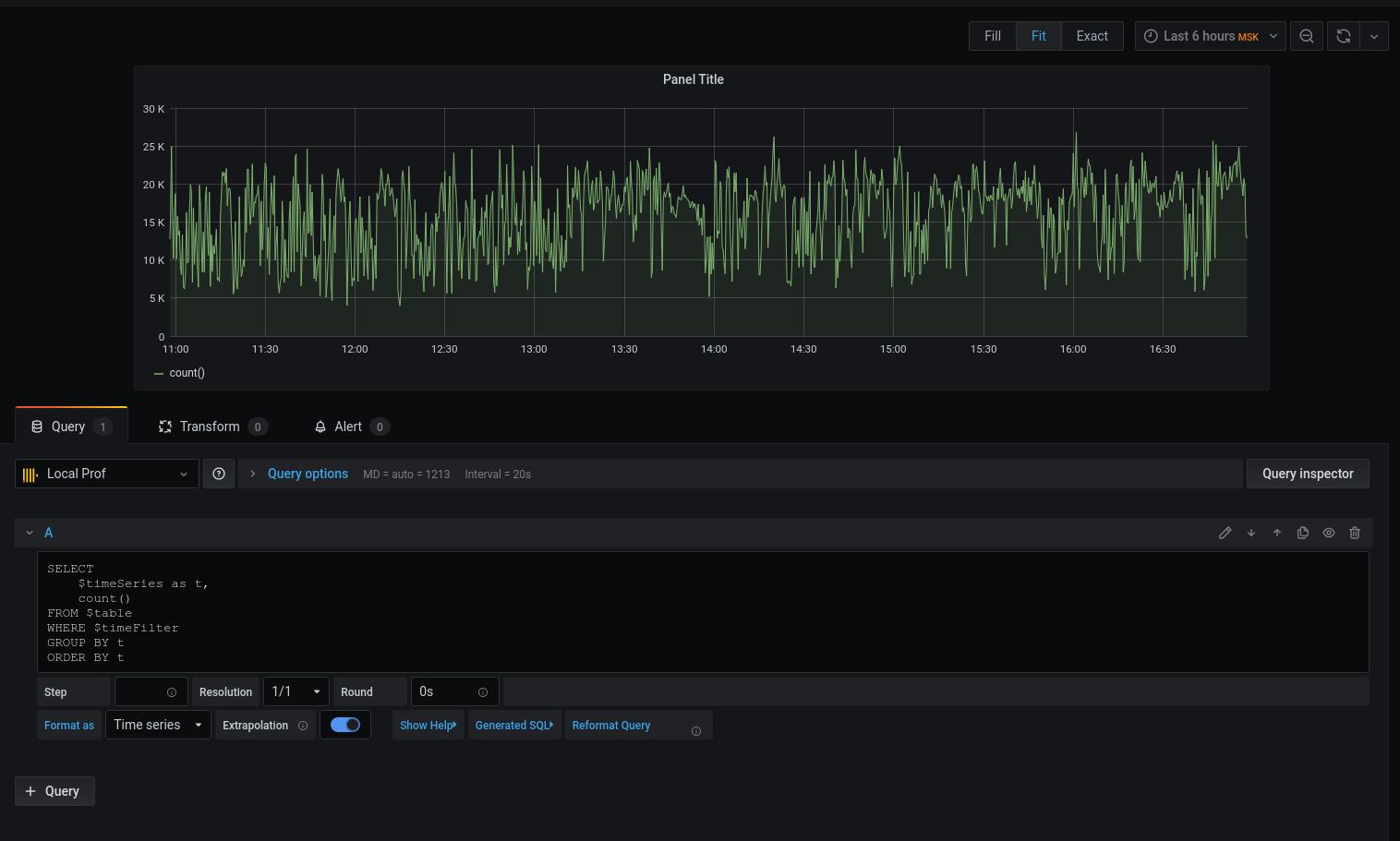
wir mit der Abfrage fort: Wir haben ein Diagramm, aber ich möchte Einzelheiten. Drucken wir die durchschnittliche Latenz, die das Datum mit der Zeit bis zum Beginn des Fünf-Minuten-Intervalls rundet :
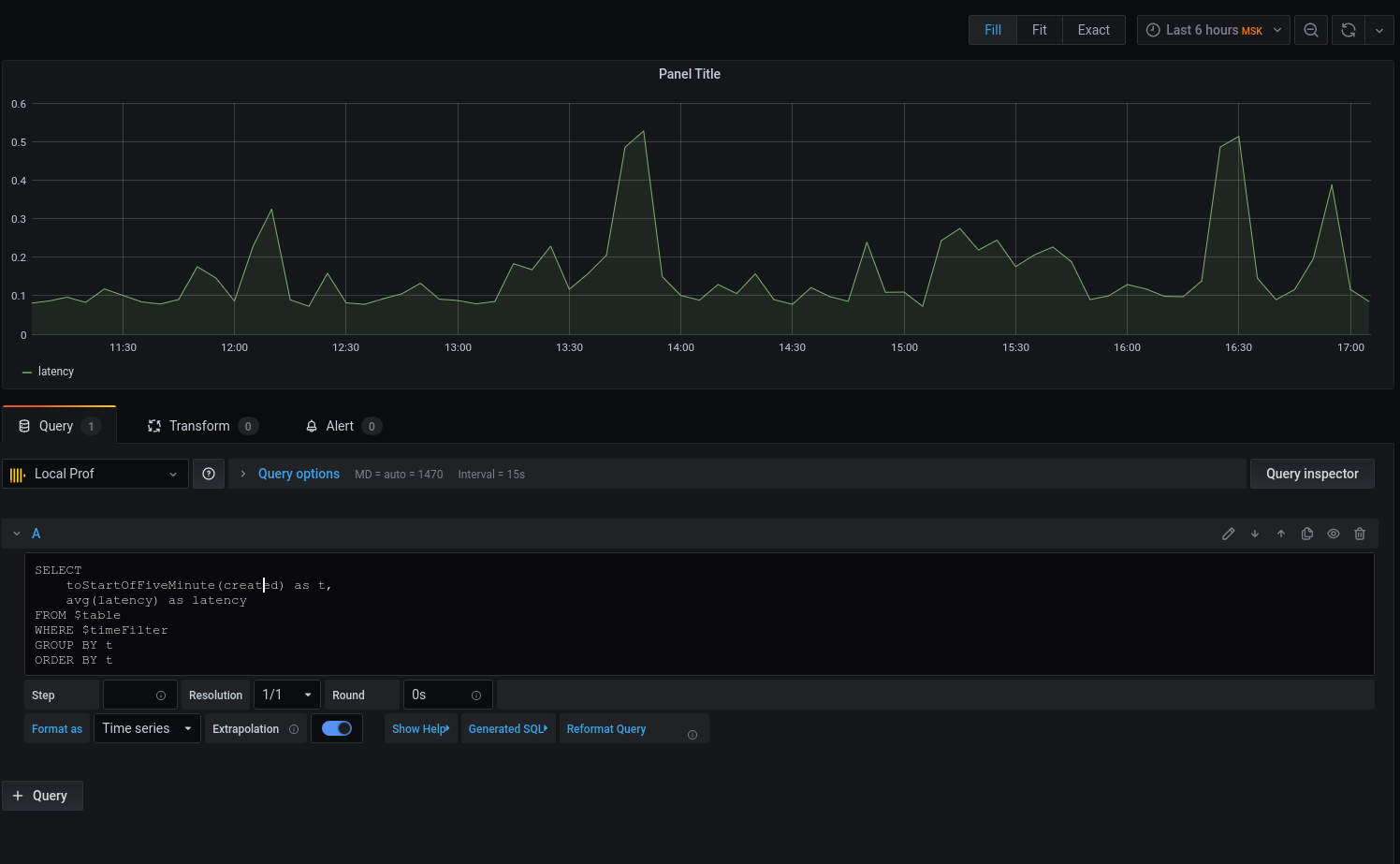
Jetzt werden die ausgewählten Daten im Diagramm angezeigt, wir können uns auf sie konzentrieren. Konfigurieren Sie für Warnungen Trigger, Gruppieren nach Ereignissen und vieles mehr.
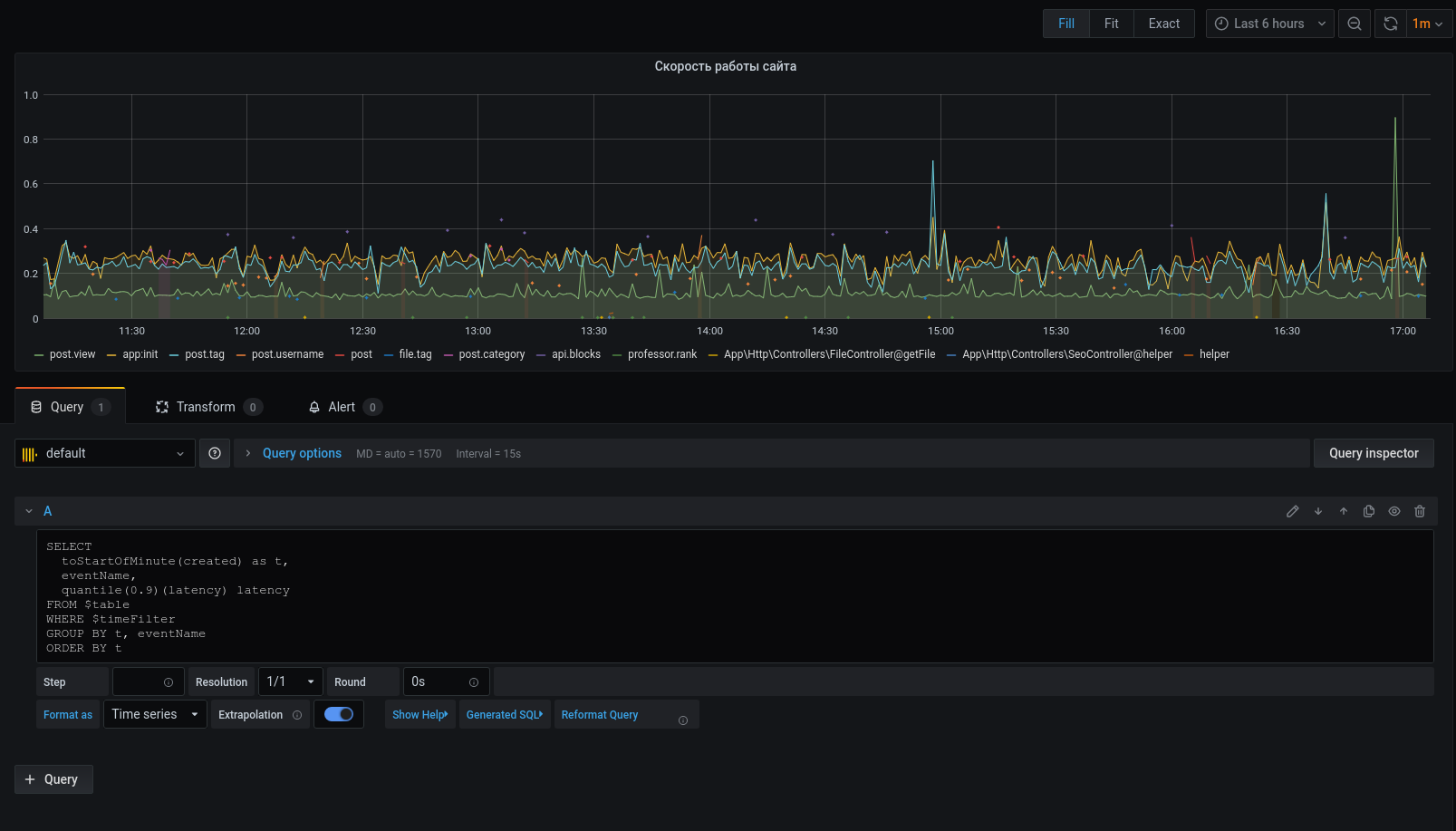
Der Profiler ist kein Ersatz für die Tools: xhprof (Facebook) , xhprof (Gezeiten) , liveprof von (Badoo) . Und ergänzt sie nur.
Der gesamte Quellcode basiert auf Github - Profiler-Modell , Service , BulkWriteCommand , BulkWriterJob und Middleware ( 1 , 2 ).
Paket installieren:
composer req bavix/laravel-profWenn Sie Verbindungen einrichten (config / database.php), fügen Sie clickhouse hinzu:
'bavix::clickhouse' => [
'driver' => 'bavix::clickhouse',
'host' => env('CH_HOST'),
'port' => env('CH_PORT'),
'database' => env('CH_DATABASE'),
'username' => env('CH_USERNAME'),
'password' => env('CH_PASSWORD'),
],
Arbeitsbeginn:
use Bavix\Prof\Services\ProfileLogService;
// ...
app(ProfileLogService::class)->tick('event-name');
//
app(ProfileLogService::class)->tick('event-name');Um einen Stapel an die Warteschlange zu senden, müssen Sie cron einen Befehl hinzufügen:
* * * * * php /var/www/site.com/artisan entry:bulkSie müssen auch einen Verbraucher betreiben:
php artisan queue:work --sleep=3 --tries=3Es wird empfohlen, den Supervisor zu konfigurieren . Konfiguration (5 Verbraucher):
[program:bulk_write]
process_name=%(program_name)s_%(process_num)02d
command=php /var/www/site.com/artisan queue:work --sleep=3 --tries=3
autostart=true
autorestart=true
user=www-data
numprocs=5
redirect_stderr=true
stopwaitsecs=3600
UPD:
1. ClickHouse kann Daten nativ aus der Kafka-Warteschlange abrufen . Danke,sdm