Einführung
Die Architektur des RetinaNet des Convolutional Neural Network (CNN) besteht aus 4 Hauptteilen, von denen jeder seinen eigenen Zweck hat:
a) Backbone - das Hauptnetzwerk (Basisnetzwerk), mit dem Merkmale aus dem Eingabebild extrahiert werden. Dieser Teil des Netzwerks ist variabel und kann neuronale Klassifizierungsnetzwerke wie ResNet, VGG, EfficientNet und andere umfassen.
b) Feature Pyramid Net (FPN) - ein in Form einer Pyramide aufgebautes neuronales Faltungsnetzwerk, das dazu dient, die Vorteile von Merkmalskarten der unteren und oberen Ebene des Netzwerks zu kombinieren. Erstere haben eine hohe Auflösung, aber eine geringe semantische Generalisierungsfähigkeit. Letzteres im Gegenteil;
c) Klassifizierungssubnetz - ein Subnetz, das Informationen über Objektklassen aus FPN extrahiert und das Klassifizierungsproblem löst;
d) Regressionssubnetz - Ein Subnetz, das Informationen über die Koordinaten von Objekten im Bild aus FPN extrahiert und so das Regressionsproblem löst.
In Abb. 1 zeigt die Architektur des RetinaNet mit dem neuronalen ResNet-Netzwerk als Backbone.
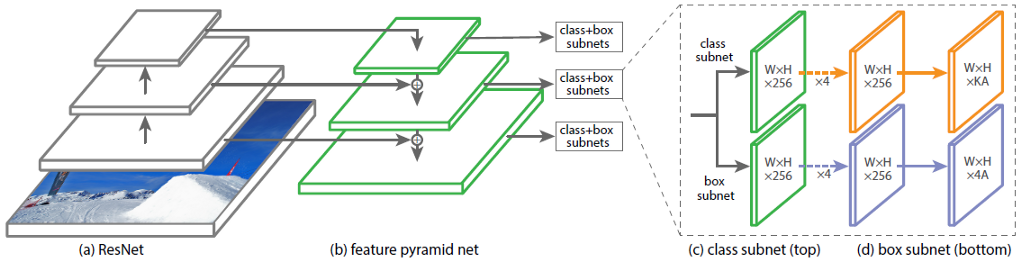
Abbildung 1 - RetinaNet-Architektur mit einem ResNet-Backbone
Lassen Sie uns jeden der in Abbildung 1 gezeigten RetinaNet-Teile im Detail analysieren . 1.
Das Backbone ist Teil des RetinaNet-Netzwerks
Da der Teil der RetinaNet-Architektur, der ein Bild als Eingabe akzeptiert und wichtige Merkmale hervorhebt, variabel ist und die aus diesem Teil extrahierten Informationen in den nächsten Schritten verarbeitet werden, ist es wichtig, ein geeignetes Backbone-Netzwerk auszuwählen, um die besten Ergebnisse zu erzielen.
Jüngste Forschungen zur CNN-Optimierung haben zur Entwicklung von Klassifizierungsmodellen geführt, die alle zuvor entwickelten Architekturen mit den besten Genauigkeitsraten für den ImageNet-Datensatz übertreffen und gleichzeitig die Effizienz um das Zehnfache verbessern. Diese Netzwerke wurden EfficientNet-B (0-7) genannt. Die Indikatoren der Familie neuer Netzwerke sind in Abb. 1 dargestellt. 2.
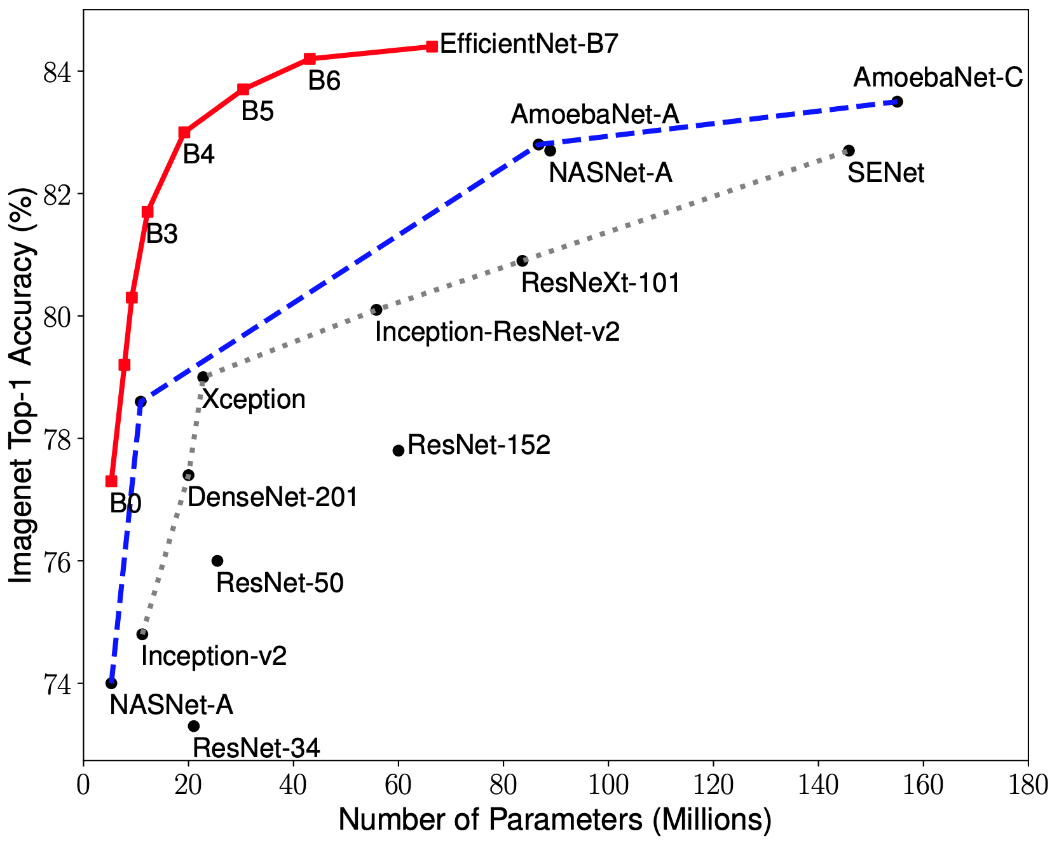
Abbildung 2 - Diagramm der Abhängigkeit des Indikators mit der höchsten Genauigkeit von der Anzahl der Netzwerkgewichte für verschiedene Architekturen
Die Zeichenpyramide
Das Feature Pyramid Network besteht aus drei Hauptteilen: Bottom-Up-Pfad, Top-Down-Pfad und seitliche Verbindungen.
Der Aufwärtspfad ist eine Art hierarchische "Pyramide" - in unserem Fall eine Folge von Faltungsschichten mit abnehmender Dimension - ein Backbone-Netzwerk. Die oberen Schichten des Faltungsnetzwerks haben eine semantischere Bedeutung, aber im Gegensatz dazu eine niedrigere Auflösung und die unteren (Abb. 3). Der Bottom-up-Pfad weist eine Sicherheitsanfälligkeit bei der Merkmalsextraktion auf - der Verlust wichtiger Informationen über ein Objekt, beispielsweise aufgrund des Rauschens eines kleinen, aber signifikanten Objekts im Hintergrund, da die Informationen am Ende des Netzwerks stark komprimiert und verallgemeinert sind.
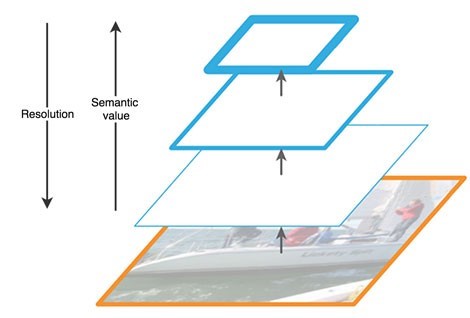
Abbildung 3 - Merkmale von Merkmalskarten auf verschiedenen Ebenen des neuronalen Netzwerks
Der absteigende Weg ist auch eine "Pyramide". Die Merkmalskarten der oberen Schicht dieser Pyramide haben die Größe der Merkmalskarten der oberen Schicht des Bottom-Up der Pyramide und werden nach der Methode des nächsten Nachbarn (Fig. 4) nach unten verdoppelt.
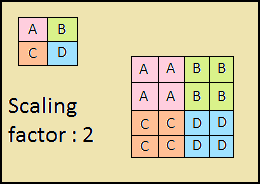
Abbildung 4 - Erhöhen der Bildauflösung durch die Methode des nächsten Nachbarn
Somit wird im Top-Down-Netzwerk jede Merkmalskarte der darüber liegenden Schicht auf die Größe der zugrunde liegenden Karte erhöht. Darüber hinaus sind in FPN seitliche Verbindungen vorhanden, was bedeutet, dass Feature-Maps der entsprechenden Bottom-Up- und Top-Down-Schichten der Pyramiden Element für Element hinzugefügt werden und die Maps von Bottom-Up 1 * 1 gefaltet werden. Dieser Vorgang ist in Abb. 1 schematisch dargestellt. 5.
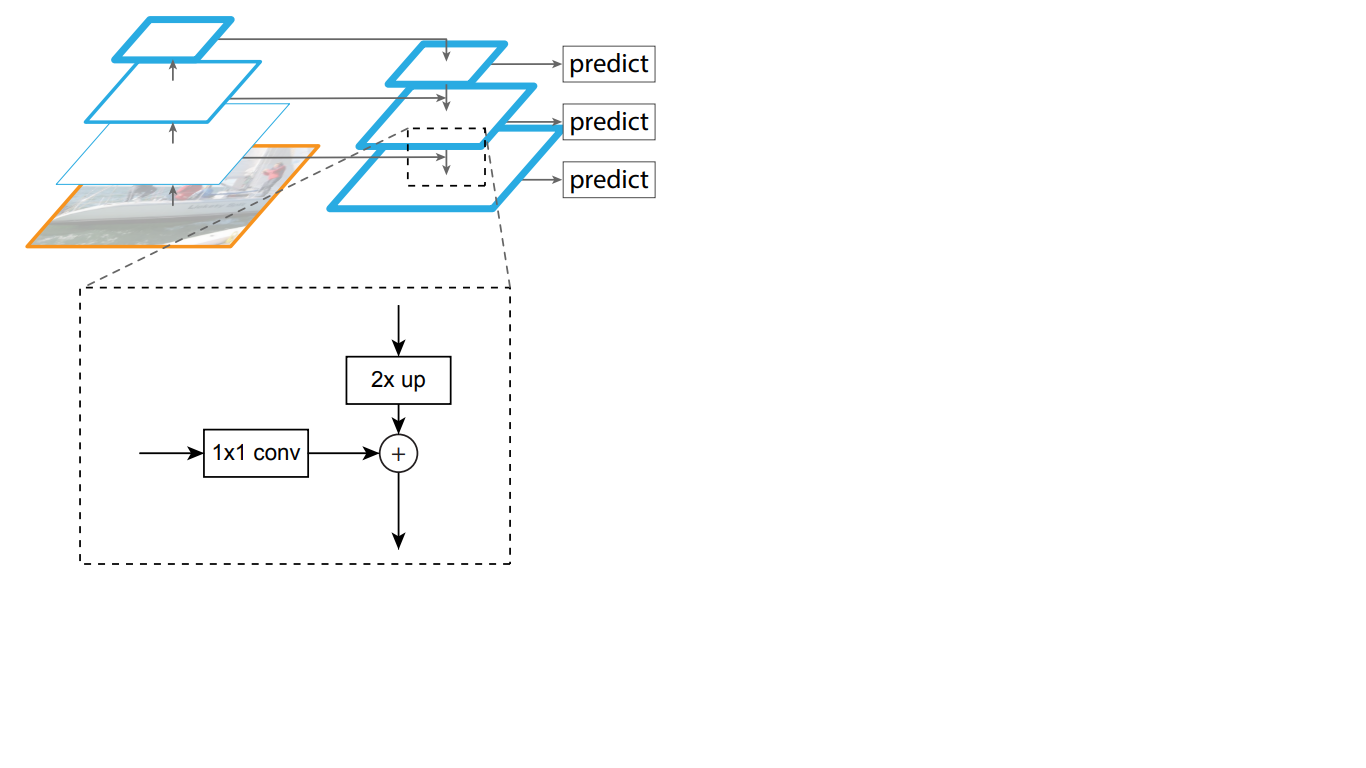
Abbildung 5 - Die Struktur der Zeichenpyramide
Seitliche Verbindungen lösen das Problem der Dämpfung wichtiger Signale beim Durchgang durch die Schichten, indem sie semantisch wichtige Informationen, die am Ende der ersten Pyramide empfangen wurden, mit detaillierteren Informationen kombinieren, die zuvor darin erhalten wurden.
Ferner wird jede der resultierenden Schichten in der Top-Down-Pyramide von zwei Subnetzen verarbeitet.
Subnetze für Klassifizierung und Regression
Der dritte Teil der RetinaNet-Architektur besteht aus zwei Subnetzen: Klassifizierung und Regression (Abbildung 6). Jedes dieser Subnetze bildet am Ausgang eine Antwort über die Klasse des Objekts und seine Position auf dem Bild. Lassen Sie uns überlegen, wie jeder von ihnen funktioniert.
Abbildung 6 - RetinaNet-Subnetze
Der Unterschied in den Prinzipien der betrachteten Blöcke (Subnetze) unterscheidet sich erst in der letzten Schicht. Jeder von ihnen besteht aus 4 Schichten von Faltungsnetzwerken. In der Ebene werden 256 Feature-Maps gebildet. Auf der fünften Ebene ändert sich die Anzahl der Feature-Maps: Das Regressions-Subnetz verfügt über 4 * A-Feature-Maps, das Klassifizierungs-Subnetz über K * A-Feature-Maps, wobei A die Anzahl der Ankerrahmen ist (detaillierte Beschreibung der Ankerrahmen im nächsten Unterabschnitt), K die Anzahl der Objektklassen.
In der letzten, sechsten Ebene wird jede Merkmalskarte in einen Satz von Vektoren transformiert. Das Regressionsmodell am Ausgang hat für jede Ankerbox einen Vektor von 4 Werten, der den Versatz der Grundwahrheitsbox relativ zur Ankerbox angibt. Das Klassifizierungsmodell hat am Ausgang für jeden Ankerrahmen einen One-Hot-Vektor der Länge K, in dem der Index mit dem Wert 1 der Klassennummer entspricht, die das neuronale Netzwerk dem Objekt zugewiesen hat.
Ankerrahmen
Im letzten Abschnitt wurde der Begriff Ankerrahmen verwendet. Die Ankerbox ist ein Hyperparameter von Detektoren für neuronale Netze, ein vordefiniertes Begrenzungsrechteck, in Bezug auf das das Netzwerk arbeitet.
Angenommen, das Netzwerk verfügt über eine 3 * 3-Feature-Map am Ausgang. In RetinaNet verfügt jede Zelle über 9 Ankerboxen mit jeweils unterschiedlicher Größe und unterschiedlichem Seitenverhältnis (Abbildung 7). Während des Trainings werden Ankerrahmen an jeden Zielrahmen angepasst. Wenn ihr IoU-Indikator einen Wert von 0,5 hat, wird der Ankerrahmen als Ziel zugewiesen. Wenn der Wert kleiner als 0,4 ist, wird er als Hintergrund betrachtet. In anderen Fällen wird der Ankerrahmen für das Training ignoriert. Das Klassifizierungsnetzwerk wird relativ zur Zuordnung (Objektklasse oder Hintergrund) trainiert, das Regressionsnetzwerk wird relativ zu den Koordinaten des Ankerrahmens trainiert (es ist wichtig zu beachten, dass der Fehler relativ zum Ankerrahmen berechnet wird, nicht jedoch zum Zielrahmen).
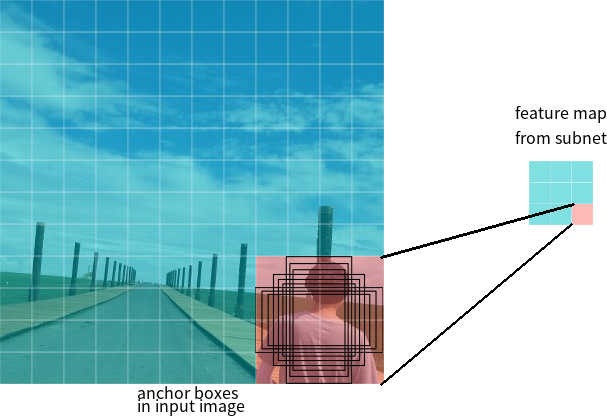
Abbildung 7 - Ankerrahmen für eine Zelle der Feature-Map mit einer Größe von 3 * 3
Verlustfunktionen
RetinaNet-Verluste sind zusammengesetzt und bestehen aus zwei Werten: dem Regressions- oder Lokalisierungsfehler (unten als Lloc bezeichnet) und dem Klassifizierungsfehler (unten als Lcls bezeichnet). Die allgemeine Verlustfunktion kann wie folgt geschrieben werden:
Dabei ist λ ein Hyperparameter, der das Gleichgewicht zwischen den beiden Verlusten steuert.
Betrachten wir die Berechnung der einzelnen Verluste genauer.
Wie zuvor beschrieben, wird jedem Zielrahmen ein Anker zugewiesen. Bezeichnen wir diese Paare als (Ai, Gi) i = 1, ... N, wobei A den Anker darstellt, G der Zielrahmen ist und N die Anzahl der übereinstimmenden Paare ist.
Für jeden Anker sagt das Regressionsnetzwerk 4 Zahlen voraus, die als Pi = (Pix, Piy, Piw, Pih) bezeichnet werden können. Die ersten beiden Paare repräsentieren den vorhergesagten Unterschied zwischen den Koordinaten der Zentren des Ankers Ai und des Zielrahmens Gi, und die letzten beiden repräsentieren den vorhergesagten Unterschied zwischen ihrer Breite und Höhe. Dementsprechend wird Ti für jeden Zielrahmen als Differenz zwischen dem Anker- und dem Zielrahmen berechnet:
Wobei glattL1 (x) durch die folgende Formel definiert ist:
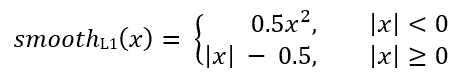
Der Verlust des RetinaNet-Klassifizierungsproblems wird unter Verwendung der Fokusverlustfunktion berechnet.
Dabei ist K die Anzahl der Klassen, yi der Zielwert der Klasse, p die Wahrscheinlichkeit der Vorhersage der i-ten Klasse, γ der Fokusparameter und α der Bias-Koeffizient. Diese Funktion ist eine erweiterte Kreuzentropiefunktion. Der Unterschied liegt in der Addition des Parameters γ∈ (0, + ∞), der das Problem des Klassenungleichgewichts löst. Während des Trainings sind die meisten vom Klassifizierer verarbeiteten Objekte der Hintergrund, bei dem es sich um eine separate Klasse handelt. Daher kann ein Problem auftreten, wenn das neuronale Netzwerk lernt, den Hintergrund besser als andere Objekte zu bestimmen. Das Hinzufügen eines neuen Parameters löste dieses Problem, indem der Fehlerwert für leicht zu klassifizierende Objekte reduziert wurde. Die Diagramme der Fokus- und Kreuzentropiefunktionen sind in Fig. 8 gezeigt.
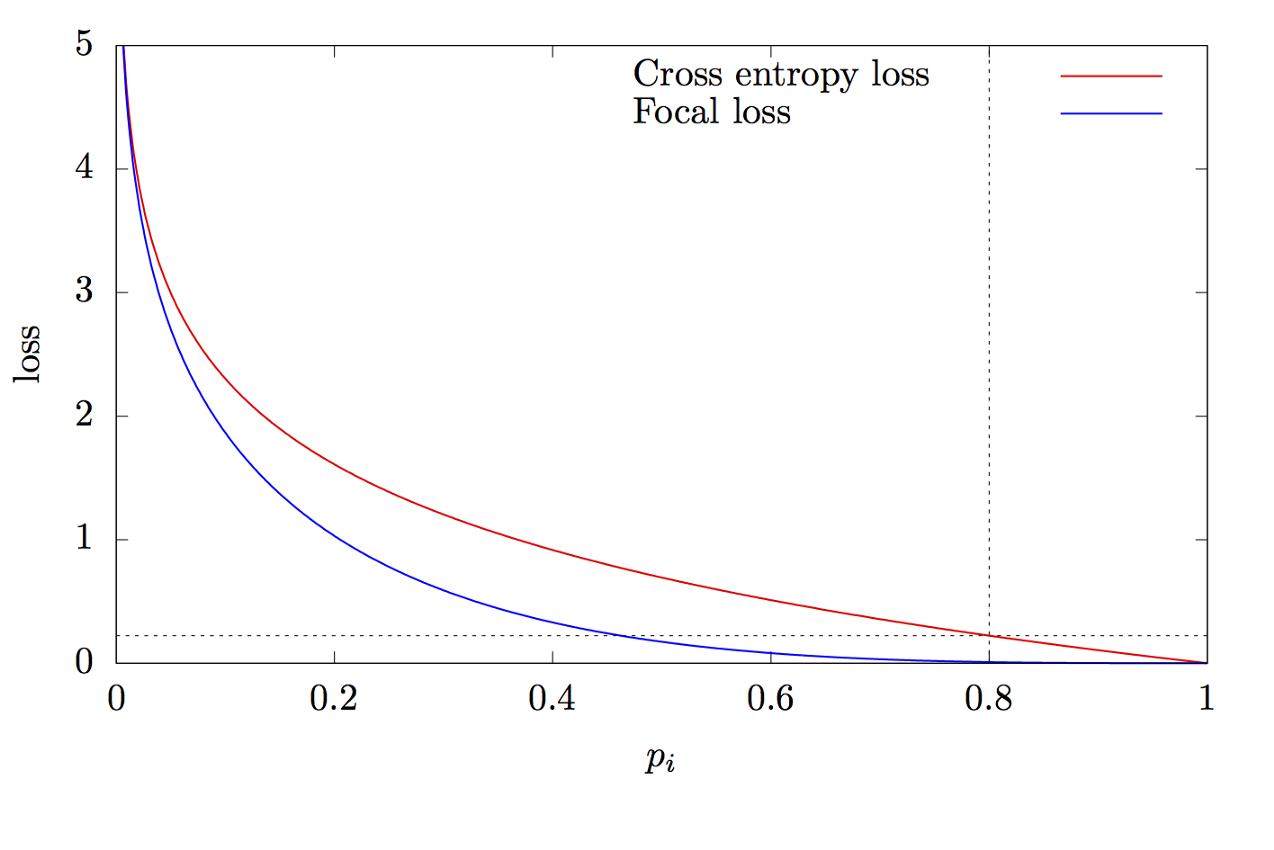
Abbildung 8 - Diagramme der Fokus- und Kreuzentropiefunktionen
Vielen Dank für das Lesen dieses Artikels!
Liste der Quellen:
- Tan M., Le Q. V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. 2019. URL: arxiv.org/abs/1905.11946
- Zeng N. RetinaNet Explained and Demystified [ ]. 2018 URL: blog.zenggyu.com/en/post/2018-12-05/retinanet-explained-and-demystified
- Review: RetinaNet — Focal Loss (Object Detection) [ ]. 2019 URL: towardsdatascience.com/review-retinanet-focal-loss-object-detection-38fba6afabe4
- Tsung-Yi Lin Focal Loss for Dense Object Detection. 2017. URL: arxiv.org/abs/1708.02002
- The intuition behind RetinaNet [ ]. 2018 URL: medium.com/@14prakash/the-intuition-behind-retinanet-eb636755607d