
Das maschinelle Lernen verlagert sich immer mehr von handgefertigten Modellen zu automatisch optimierten Pipelines mit Tools wie H20 , TPOT und Auto-Sklearn . Diese Bibliotheken zielen zusammen mit Techniken wie der Zufallssuche darauf ab, die Modellauswahl zu vereinfachen und Teile des maschinellen Lernens zu optimieren, indem das beste Modell für einen Datensatz ohne manuellen Eingriff gefunden wird. Die Objektentwicklung, wohl der wertvollere Aspekt von Pipelines für maschinelles Lernen, bleibt jedoch fast ausschließlich menschlich.
Konstruktionsmerkmale ( Feature Engineering), auch als Feature-Erstellung bezeichnet, ist der Prozess des Erstellens neuer Features aus vorhandenen Daten, um ein Modell für maschinelles Lernen zu trainieren. Dieser Schritt ist möglicherweise wichtiger als das tatsächlich verwendete Modell, da der Algorithmus für maschinelles Lernen nur aus den von uns bereitgestellten Daten lernt und das Erstellen von Funktionen, die für die Aufgabe relevant sind, unbedingt erforderlich ist (siehe den hervorragenden Artikel „Ein paar nützliche Dinge“ Wissenswertes zum maschinellen Lernen " ).
In der Regel ist die Feature-Entwicklung ein langwieriger manueller Prozess, der auf Domänenwissen, Intuition und Datenmanipulation basiert. Dieser Prozess kann äußerst langwierig sein und die Endmerkmale werden sowohl durch die menschliche Subjektivität als auch durch die Zeit begrenzt. Das automatisierte Feature-Design soll dem Datenwissenschaftler helfen, automatisch viele Kandidatenobjekte aus einem Datensatz zu erstellen, aus dem die besten ausgewählt und für das Training verwendet werden können.
In diesem Artikel sehen wir uns ein Beispiel für die Verwendung der automatischen Funktionsentwicklung mit der Python featuretools-Bibliothek an.. Wir werden einen Beispieldatensatz verwenden, um die Grundlagen zu zeigen (achten Sie auf zukünftige Beiträge mit realen Daten). Der vollständige Code aus diesem Artikel ist auf GitHub verfügbar .
Grundlagen der Funktionsentwicklung
Bei der Entwicklung von Merkmalen werden zusätzliche Merkmale aus vorhandenen Daten erstellt, die häufig auf mehrere verwandte Tabellen verteilt sind. Für die Funktionsentwicklung müssen relevante Informationen aus den Daten extrahiert und in einer einzigen Tabelle zusammengefasst werden, die dann zum Trainieren eines maschinellen Lernmodells verwendet werden kann.
Das Erstellen von Merkmalen ist sehr zeitaufwändig, da normalerweise mehrere Schritte zum Erstellen jedes neuen Merkmals erforderlich sind, insbesondere wenn Informationen aus mehreren Tabellen verwendet werden. Wir können Feature-Erstellungsvorgänge in zwei Kategorien gruppieren: Transformationen und Aggregationen . Schauen wir uns einige Beispiele an, um diese Konzepte in Aktion zu sehen.
Transformationwirkt auf eine einzelne Tabelle (in Python-Begriffen ist eine Tabelle nur Pandas
DataFrame) und erstellt neue Funktionen aus einer oder mehreren vorhandenen Spalten. Zum Beispiel, wenn wir die Kundentabelle unten haben,
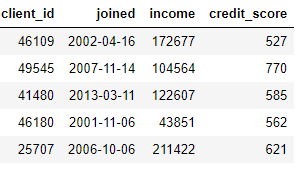
Wir können Features erstellen, indem wir den Monat aus einer Spalte ermitteln
joinedoder den natürlichen Logarithmus aus einer Spalte entnehmen income. Dies sind beide Transformationen, da sie nur Informationen aus einer Tabelle verwenden.
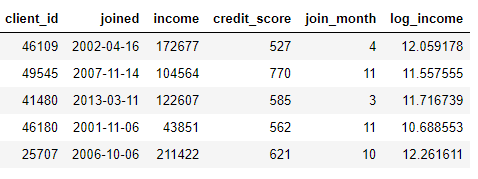
Auf der anderen Seite werden Aggregationen über Tabellen hinweg durchgeführt und verwenden eine Eins-zu-Viele-Beziehung, um Fälle zu gruppieren und dann Statistiken zu berechnen. Wenn wir beispielsweise eine andere Tabelle mit Informationen zu Kundenkrediten haben, in der jeder Kunde mehrere Kredite haben kann, können wir Statistiken wie durchschnittliche, maximale und minimale Kreditwerte für jeden Kunden berechnen.
Dieser Prozess umfasst das Gruppieren der Darlehenstabelle nach Kunden, das Berechnen der Aggregation und das anschließende Kombinieren der empfangenen Daten mit den Kundendaten. So könnten wir es in Python mit der Pandas-Sprache machen .
import pandas as pd
# Group loans by client id and calculate mean, max, min of loans
stats = loans.groupby('client_id')['loan_amount'].agg(['mean', 'max', 'min'])
stats.columns = ['mean_loan_amount', 'max_loan_amount', 'min_loan_amount']
# Merge with the clients dataframe
stats = clients.merge(stats, left_on = 'client_id', right_index=True, how = 'left')
stats.head(10)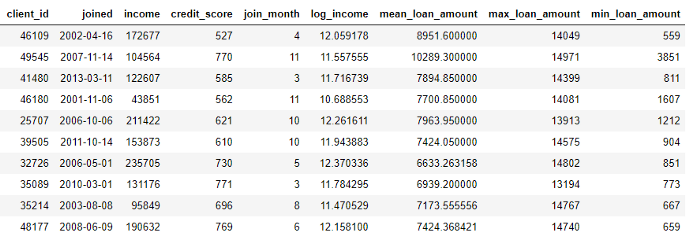
Diese Operationen sind an sich nicht kompliziert, aber wenn wir Hunderte von Variablen haben, die über Dutzende von Tabellen verteilt sind, kann dieser Prozess nicht manuell durchgeführt werden. Idealerweise benötigen wir eine Lösung, die automatisch Transformationen und Aggregationen über mehrere Tabellen hinweg durchführen und die resultierenden Daten in einer Tabelle kombinieren kann. Obwohl Pandas eine großartige Ressource ist, gibt es immer noch viele Datenmanipulationen, die wir manuell durchführen möchten! (Weitere Informationen zum manuellen Entwerfen von Funktionen finden Sie im hervorragenden Python Data Science-Handbuch .)
Featuretools
Glücklicherweise ist featuretools genau die Lösung, nach der wir suchen. Diese Open-Source-Python-Bibliothek generiert automatisch viele Merkmale aus einer Reihe verwandter Tabellen. Featuretools basiert auf einer Technik namens " Deep Feature Synthesis ", die viel beeindruckender klingt als sie tatsächlich ist (der Name kommt von der Kombination mehrerer Funktionen, nicht weil sie Deep Learning verwendet!).
Deep Feature Synthesis kombiniert mehrere Transformations- und Aggregationsoperationen (sogenannte Feature-Primitive)im FeatureTools-Wörterbuch), um Features aus Daten zu erstellen, die auf viele Tabellen verteilt sind. Wie die meisten Ideen im maschinellen Lernen ist es eine komplexe Methode, die auf einfachen Konzepten basiert. Indem wir jeweils einen Baustein studieren, können wir ein gutes Verständnis für diese leistungsstarke Technik gewinnen.
Schauen wir uns zunächst die Daten aus unserem Beispiel an. Wir haben bereits etwas aus dem obigen Datensatz gesehen, und der gesamte Satz von Tabellen sieht folgendermaßen aus:
clients: Grundlegende Informationen zu Kunden in der Kreditvereinigung. Jeder Client hat nur eine Zeile in diesem Datenrahmen
loans: Kredite an Kunden. Jedes Guthaben hat nur eine eigene Zeile in diesem Datenrahmen, Kunden können jedoch mehrere Guthaben haben.
payments: Kredit-Zahlungen. Jede Zahlung hat nur eine Zeile, aber jedes Darlehen hat mehrere Zahlungen.
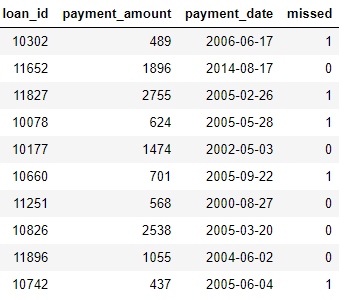
Wenn wir eine maschinelle Lernaufgabe haben, beispielsweise die Vorhersage, ob ein Kunde ein zukünftiges Darlehen zurückzahlen wird, möchten wir alle Kundeninformationen in einer Tabelle zusammenfassen. Die Tabellen sind verknüpft (über die Variablen
client_idund loan_id), und wir können eine Reihe von Transformationen und Aggregationen verwenden, um den Prozess manuell abzuschließen. Wir werden jedoch bald sehen, dass wir stattdessen featuretools verwenden können, um den Prozess zu automatisieren.
Entities und EntitySets (Entities und Entity Sets)
Die ersten beiden Konzepte von featuretools sind Entitäten und Entitätssätze . Entität ist nur eine Tabelle (oder
DataFramewenn Sie in Pandas denken). EntitySet ist eine Sammlung von Tabellen und Beziehungen zwischen ihnen. Stellen Sie sich vor, Entityset ist nur eine weitere Python-Datenstruktur mit eigenen Methoden und Attributen.
Wir können eine leere Menge von Entitäten in featuretools wie folgt erstellen:
import featuretools as ft
# Create new entityset
es = ft.EntitySet(id = 'clients')Jetzt müssen wir Entitäten hinzufügen. Jede Entität muss einen Index haben, der eine Spalte mit allen eindeutigen Elementen ist. Das heißt, jeder Wert im Index darf nur einmal in der Tabelle erscheinen. Der Index im Datenrahmen
clientsist, client_idweil jeder Client nur eine Zeile in diesem Datenrahmen hat. Wir fügen dem Entitätssatz eine Entität mit einem vorhandenen Index mit der folgenden Syntax hinzu:
# Create an entity from the client dataframe
# This dataframe already has an index and a time index
es = es.entity_from_dataframe(entity_id = 'clients', dataframe = clients,
index = 'client_id', time_index = 'joined')Der Datenrahmen
loanshat auch einen eindeutigen Index loan_id, und die Syntax zum Hinzufügen zu einem Entitätssatz ist dieselbe wie für clients. Es gibt jedoch keinen eindeutigen Index für den Zahlungsdatenrahmen. Wenn wir diese Entität zum Entitätssatz hinzufügen, müssen wir einen Parameter übergeben make_index = Trueund den Indexnamen angeben. Während featuretools automatisch den Datentyp jeder Spalte in einer Entität ableitet, können wir dies überschreiben, indem wir ein Wörterbuch mit Spaltentypen an den Parameter übergeben variable_types.
# Create an entity from the payments dataframe
# This does not yet have a unique index
es = es.entity_from_dataframe(entity_id = 'payments',
dataframe = payments,
variable_types = {'missed': ft.variable_types.Categorical},
make_index = True,
index = 'payment_id',
time_index = 'payment_date')Obwohl es
missedsich bei diesem Datenrahmen um eine Ganzzahl handelt, handelt es sich nicht um eine numerische Variable, da nur zwei diskrete Werte angenommen werden können. Daher weisen wir featuretools an, ihn als kategoriale Variable zu behandeln. Nachdem wir die Datenrahmen zum Entitätssatz hinzugefügt haben, untersuchen wir einen von ihnen:
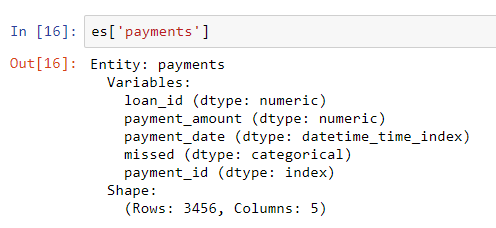
Die Spaltentypen wurden mit der angegebenen Revision korrekt abgeleitet. Als Nächstes müssen wir angeben, wie die Tabellen im Entitätssatz zusammenhängen.
Beziehungen zwischen Tabellen
Die Beziehung zwischen zwei Tabellen lässt sich am besten mit einer Eltern-Kind-Analogie darstellen . Eins-zu-viele-Beziehung: Jeder Elternteil kann mehrere Kinder haben. Im Tabellenbereich enthält die übergeordnete Tabelle eine Zeile für jedes übergeordnete Element. Die untergeordnete Tabelle kann jedoch mehrere Zeilen enthalten, die mehreren untergeordneten Elementen desselben übergeordneten Elements entsprechen.
In unserem Datensatz ist der
clientsFrame beispielsweise das übergeordnete Element des loansFrames. Jeder Client hat nur eine Zeile clients, kann aber mehrere Zeilen enthalten loans. Ebenso loanssind Elternpaymentsweil jedes Darlehen mehrere Zahlungen hat. Eltern sind durch eine gemeinsame Variable mit ihren Kindern verbunden. Wenn wir die Aggregation durchführen, gruppieren wir die untergeordnete Tabelle nach der übergeordneten Variablen und berechnen Statistiken über die untergeordneten Elemente jedes übergeordneten Elements.
Um die Beziehung in featuretools zu formalisieren , müssen wir nur eine Variable angeben, die die beiden Tabellen miteinander verbindet.
clientsund die Tabelle ist loansder Variablen zugeordnet client_id, und loans, und payments- mit Hilfe von loan_id. Die Syntax zum Erstellen und Hinzufügen einer Beziehung zu einem Entitätssatz ist nachstehend aufgeführt:
# Relationship between clients and previous loans
r_client_previous = ft.Relationship(es['clients']['client_id'],
es['loans']['client_id'])
# Add the relationship to the entity set
es = es.add_relationship(r_client_previous)
# Relationship between previous loans and previous payments
r_payments = ft.Relationship(es['loans']['loan_id'],
es['payments']['loan_id'])
# Add the relationship to the entity set
es = es.add_relationship(r_payments)
es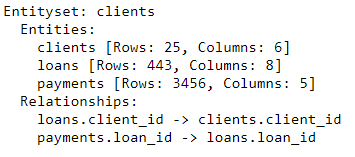
Der Entitätssatz enthält jetzt drei Entitäten (Tabellen) und Beziehungen, die diese Entitäten miteinander verbinden. Nach dem Hinzufügen von Entitäten und dem Formalisieren von Beziehungen ist unser Satz von Entitäten vollständig und wir können Features erstellen.
Feature-Grundelemente
Bevor wir uns vollständig mit der tiefen Synthese von Merkmalen befassen können, müssen wir die Grundelemente von Merkmalen verstehen . Wir wissen bereits, was sie sind, aber wir nennen sie einfach bei verschiedenen Namen! Dies sind nur die grundlegenden Operationen, mit denen wir neue Funktionen erstellen:
- Aggregationen: Vorgänge, die für eine Eltern-Kind-Beziehung (Eins-zu-Viele) ausgeführt werden, die nach Eltern gruppiert sind und Statistiken für Kinder berechnen. Ein Beispiel ist das Gruppieren einer Tabelle
loansnachclient_idund das Bestimmen des maximalen Kreditbetrags für jeden Kunden. - Konvertierungen: Vorgänge, die von einer Tabelle in eine oder mehrere Spalten ausgeführt werden. Beispiele sind die Differenz zwischen zwei Spalten in derselben Tabelle oder der Absolutwert einer Spalte.
Mit diesen Grundelementen werden neue Funktionen in featuretools erstellt, entweder für sich oder als mehrere Grundelemente. Unten finden Sie eine Liste einiger Grundelemente in featuretools (wir können auch benutzerdefinierte Grundelemente definieren ):
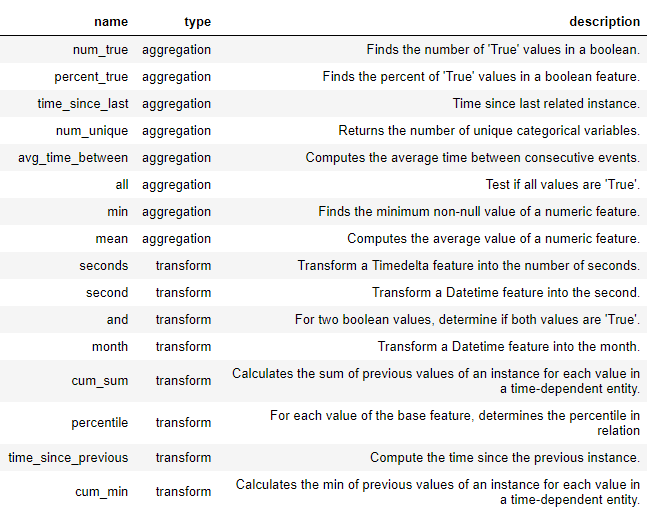
Diese Grundelemente können einzeln oder kombiniert verwendet werden, um Features zu erstellen. Um Features mit den angegebenen Grundelementen zu erstellen, verwenden wir eine Funktion
ft.dfs(steht für Deep Feature Synthesis). Wir übergeben eine Reihe von Entitäten target_entity, eine Tabelle, zu der wir die ausgewählten Features trans_primitives(Transformationen) und agg_primitives(Aggregate) hinzufügen möchten :
# Create new features using specified primitives
features, feature_names = ft.dfs(entityset = es, target_entity = 'clients',
agg_primitives = ['mean', 'max', 'percent_true', 'last'],
trans_primitives = ['years', 'month', 'subtract', 'divide'])Das Ergebnis ist ein Datenrahmen mit neuen Funktionen für jeden Client (weil wir Clients erstellt haben
target_entity). Zum Beispiel haben wir einen Monat, in dem jeder Client beigetreten ist, was ein Transformationsprimitiv ist:
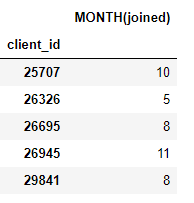
Wir haben auch eine Reihe von Aggregationsprimitiven, wie z. B. die durchschnittlichen Zahlungsbeträge für jeden Kunden:
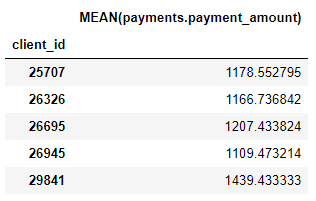
Obwohl wir nur einige Grundelemente angegeben haben, hat featuretools durch Kombinieren und Stapeln dieser Grundelemente viele neue Funktionen erstellt.
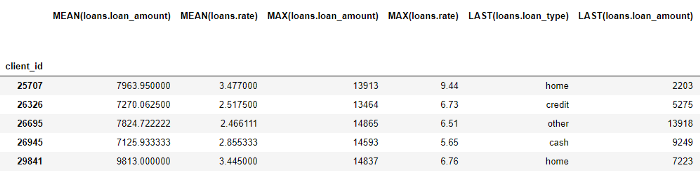
Der gesamte Datenrahmen enthält 793 Spalten mit neuen Funktionen!
Tiefe Synthese von Zeichen
Wir haben jetzt alles, um die Deep Feature Synthesis (dfs) zu verstehen. Tatsächlich haben wir dfs bereits im vorherigen Funktionsaufruf ausgeführt! Ein tiefes Merkmal ist einfach ein Merkmal, das aus einer Kombination mehrerer Grundelemente besteht, und dfs ist der Name des Prozesses, der diese Merkmale erzeugt. Die Tiefe eines tiefen Features ist die Anzahl der Grundelemente, die zum Erstellen eines Features erforderlich sind.
Eine Spalte
MEAN (payment.payment_amount)ist beispielsweise ein tiefes Feature mit einer Tiefe von 1, da sie mit einer einzelnen Aggregation erstellt wurde. Ein Element mit einer Tiefe von zwei ist dies LAST(loans(MEAN(payment.payment_amount)). Dazu werden zwei Aggregationen kombiniert: LAST (aktuell) zusätzlich zu MEAN. Dies ist die durchschnittliche Zahlung für das letzte Darlehen für jeden Kunden.
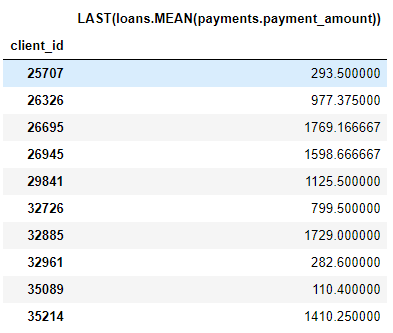
Wir können Features in jeder gewünschten Tiefe komponieren, aber in der Praxis bin ich nie über Tiefe 2 hinausgegangen. Nach diesem Punkt sind Features schwer zu interpretieren, aber ich fordere jeden Interessierten auf, zu versuchen, „tiefer zu gehen“ .
Wir müssen die Grundelemente nicht manuell angeben, sondern können die featuretools automatisch Funktionen für uns auswählen lassen. Dafür verwenden wir den gleichen Funktionsaufruf
ft.dfs, übergeben aber keine Grundelemente:
# Perform deep feature synthesis without specifying primitives
features, feature_names = ft.dfs(entityset=es, target_entity='clients',
max_depth = 2)
features.head()
Featuretools hat viele neue Funktionen für uns erstellt. Während dieser Prozess automatisch neue Merkmale erstellt, ersetzt er keinen Data Scientist, da wir immer noch herausfinden müssen, was mit all diesen Merkmalen zu tun ist. Wenn unser Ziel beispielsweise darin besteht, vorherzusagen, ob ein Kunde einen Kredit zurückzahlen wird, suchen wir möglicherweise nach den Zeichen, die für ein bestimmtes Ergebnis am relevantesten sind. Wenn wir Kenntnisse über das Fachgebiet haben, können wir es außerdem verwenden, um bestimmte Grundelemente von Merkmalen auszuwählen oder um Kandidatenmerkmale tief zu synthetisieren .
Nächste Schritte
Das automatisierte Feature-Design löste ein Problem, schuf jedoch ein anderes: Zu viele Features. Während es schwierig ist zu sagen, welche dieser Funktionen vor dem Anpassen eines Modells wichtig sind, sind höchstwahrscheinlich nicht alle für die Aufgabe relevant, für die wir unser Modell trainieren möchten. Darüber hinaus können zu viele Funktionen die Modellleistung beeinträchtigen, da weniger nützliche Funktionen die wichtigeren verdrängen.
Das Problem zu vieler Attribute wird als Fluch der Dimension bezeichnet . Mit zunehmender Anzahl von Merkmalen (Dimension von Daten) im Modell wird es schwieriger, die Korrespondenz zwischen Merkmalen und Zielen zu untersuchen. Tatsächlich ist die Datenmenge, die erforderlich ist, damit das Modell gut funktioniert, gleichskaliert exponentiell mit der Anzahl der Features .
Der Fluch der Dimensionalität wird mit einer Merkmalsreduzierung (auch als Merkmalsauswahl bezeichnet) kombiniert : dem Prozess des Entfernens unnötiger Merkmale. Dies kann viele Formen annehmen: Hauptkomponentenanalyse (PCA), SelectKBest unter Verwendung von Merkmalswerten aus einem Modell oder automatische Codierung unter Verwendung tiefer neuronaler Netze. Die Reduzierung von Funktionen ist jedoch ein separates Thema für einen anderen Artikel. An diesem Punkt wissen wir, dass wir featuretools verwenden können, um mit minimalem Aufwand viele Funktionen aus vielen Tabellen zu erstellen!
Ausgabe
Wie viele Themen des maschinellen Lernens ist das automatisierte Feature-Design mit featuretools ein komplexes Konzept, das auf einfachen Ideen basiert. Mithilfe der Konzepte von Gruppen von Entitäten, Entitäten und Beziehungen können featuretools eine umfassende Feature-Synthese durchführen, um neue Features zu erstellen. Die Tiefensynthese von Features kombiniert wiederum Grundelemente - Aggregate , die durch Eins-zu-Viele-Beziehungen zwischen Tabellen funktionieren , und Transformationen , Funktionen, die auf eine oder mehrere Spalten in einer Tabelle angewendet werden -, um neue Features aus mehreren Tabellen zu erstellen.

In den kostenpflichtigen Online-Kursen von SkillFactory erfahren Sie, wie Sie einen hochkarätigen Beruf von Grund auf neu aufbauen oder Ihre Fähigkeiten und Ihr Gehalt verbessern können:
- Kurs für maschinelles Lernen (12 Wochen)
- Data Science (12 )
- (9 )
- «Python -» (9 )
- DevOps (12 )
- - (8 )