kognitive Verzerrungen über versunkene Kosten (sunk cost Irrtum) ist einer der vielen schädlichen kognitiven Verzerrungen , die die Menschen zum Opfer. Dies bezieht sich auf unsere Tendenz, weiterhin Zeit zu investierenund Ressourcen für eine verlorene Sache, weil wir bereits so viel Zeit damit verbracht haben - ertrunken -, sie zu verfolgen. Der Trugschluss unter den Kosten besteht darin, länger als nötig an einem schlechten Arbeitsplatz zu bleiben, sklavisch an einem Projekt zu arbeiten, auch wenn klar ist, dass es nicht funktioniert, und ja, die langweilige, veraltete Plotbibliothek - matplotlib - weiterhin zu verwenden, wenn es welche gibt effizientere, interaktivere und ansprechendere Alternativen.
In den letzten Monaten habe ich festgestellt, dass der einzige Grund, warum ich matplotlib verwende, die Hunderte von Stunden sind, die ich mit dem Erlernen der komplexen Syntax verbracht habe . Diese Komplexität führt zu stundenlanger Frustration, wenn Sie in StackOverflow herausfinden, wie Datumsangaben formatiert oder eine zweite Y-Achse hinzugefügt werden. Glücklicherweise ist dies eine gute Zeit, um Diagramme in Python zu zeichnen, und nachdem Sie die Optionen untersucht haben , ist der klare Gewinner - in Bezug auf Benutzerfreundlichkeit, Dokumentation und Funktionalität - ein Plot . In diesem Artikel werden wir uns eingehend mit der Handlung befassen und lernen, wie Sie in kürzerer Zeit bessere Diagramme erstellen - oft mit einer einzigen Codezeile.
Der gesamte Code für diesen Artikel ist auf GitHub verfügbar . Alle Grafiken sind interaktiv und können in NBViewer angezeigt werden .
Plotly Übersicht
Paket plotly for Python - eine Bibliothek von Open Source-Software, die auf plotly.js basiert und wiederum auf d3.js basiert . Wir werden einen Wrapper über Plotly- Manschettenknöpfen verwenden, der für die Verwendung mit Pandas DataFrame entwickelt wurde. Also, unsere Stack-Manschettenknöpfe> plotly> plotly.js> d3.js - dies bedeutet, dass wir Effizienz in der Python-Programmierung mit unglaublichen interaktiven grafischen Funktionen d3 erhalten .
( Plotly selbst ist eine Grafikfirmamit mehreren Open Source-Produkten und -Tools. Die Python-Bibliothek kann kostenlos verwendet werden und wir können unbegrenzt offline Diagramme sowie bis zu 25 Diagramme online erstellen, um sie mit der Welt zu teilen .)
Alle Arbeiten in diesem Artikel wurden in Jupyter Notebook ausgeführt, wobei Plotly + Manschettenknöpfe funktionierten offline. Importieren Sie nach der Installation von Plotly und Manschettenknöpfen
pip install cufflinks plotly Folgendes, um es in Jupiter auszuführen:
# Standard plotly imports
import plotly.plotly as py
import plotly.graph_objs as go
from plotly.offline import iplot, init_notebook_mode
# Using plotly + cufflinks in offline mode
import cufflinks
cufflinks.go_offline(connected=True)
init_notebook_mode(connected=True)Einzelvariablenverteilungen: Histogramme und Boxplots
Diagramme mit einer Variablen - eindimensional ist die Standardmethode zum Starten einer Analyse, und ein Histogramm ist ein Übergangsdiagramm ( wenn auch mit einigen Problemen ) zum Zeichnen eines Verteilungsdiagramms. Hier erstellen wir anhand meiner durchschnittlichen Artikelstatistiken (Sie können hier sehen, wie Sie Ihre eigenen Statistiken erhalten oder meine verwenden ) ein interaktives Histogramm der Anzahl der
dfArtikelklatschen ( dies ist der Standard-Pandas-Datenrahmen):
df['claps'].iplot(kind='hist', xTitle='claps',
yTitle='count', title='Claps Distribution')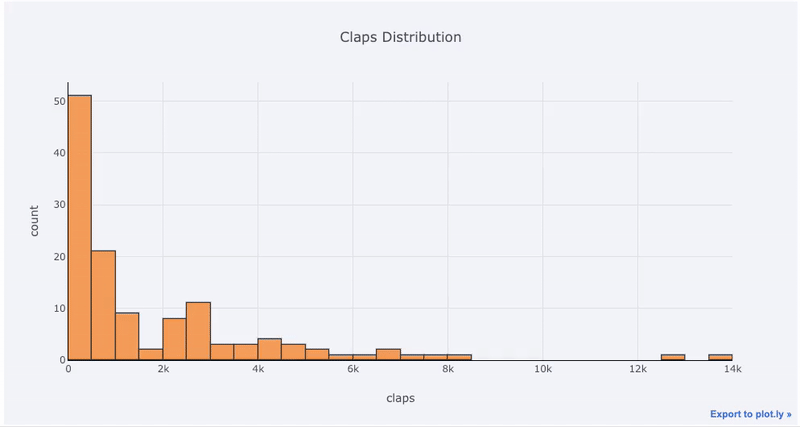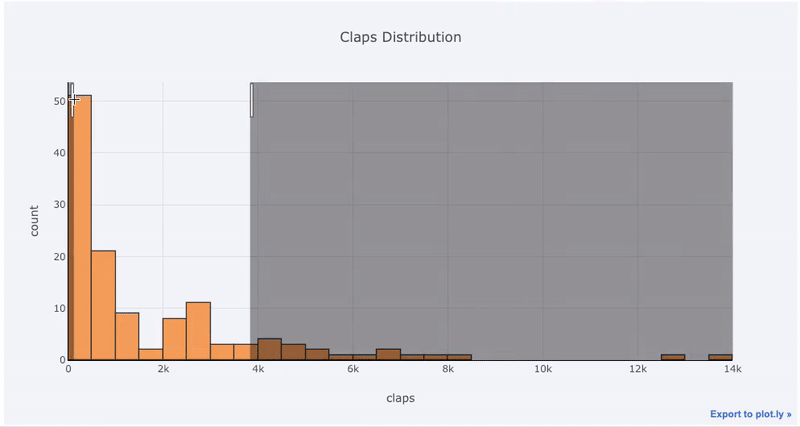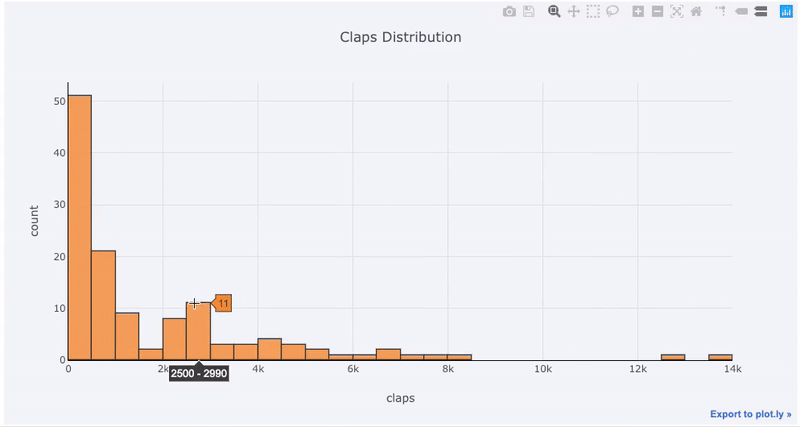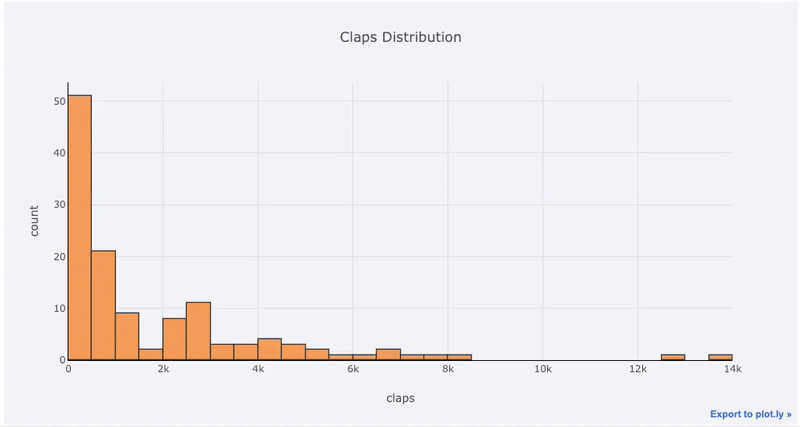
Für diejenigen, die es gewohnt sind
matplotlib, müssen wir nur noch einen Buchstaben hinzufügen ( iplotanstatt plot) und wir erhalten ein viel schöneres und interaktiveres Diagramm! Wir können auf die Daten klicken, um weitere Informationen zu erhalten, Teile des Diagramms zu vergrößern und, wie wir später sehen werden, verschiedene Kategorien auswählen.
Wenn wir überlagerte Histogramme zeichnen möchten, ist das genauso einfach:
df[['time_started', 'time_published']].iplot(
kind='hist',
histnorm='percent',
barmode='overlay',
xTitle='Time of Day',
yTitle='(%) of Articles',
title='Time Started and Time Published')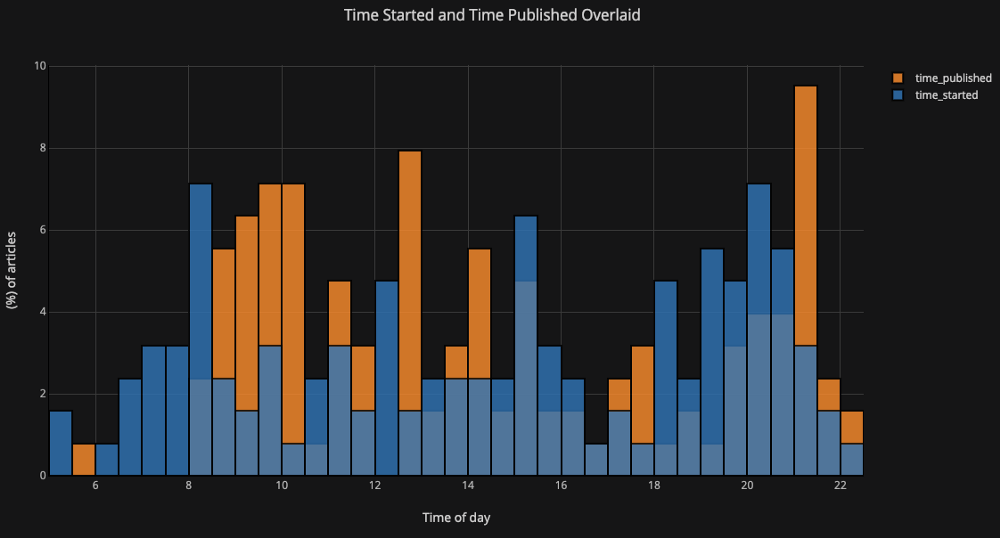
Mit ein wenig Manipulation
Pandaskönnen wir einen Barplot machen:
# Resample to monthly frequency and plot
df2 = df[['view','reads','published_date']].\
set_index('published_date').\
resample('M').mean()
df2.iplot(kind='bar', xTitle='Date', yTitle='Average',
title='Monthly Average Views and Reads')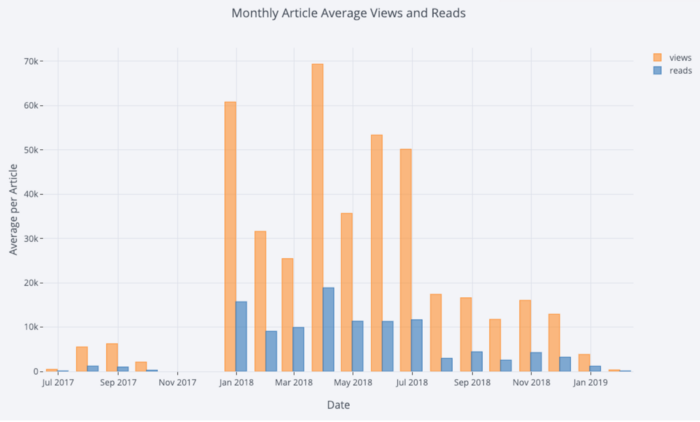
Wie wir gesehen haben, können wir die Macht der Pandas mit Plot + Manschettenknöpfen kombinieren . Um die Verteilung der Fans nach Veröffentlichung zu
pivotplotten , verwenden wir und zeichnen dann:
df.pivot(columns='publication', values='fans').iplot(
kind='box',
yTitle='fans',
title='Fans Distribution by Publication')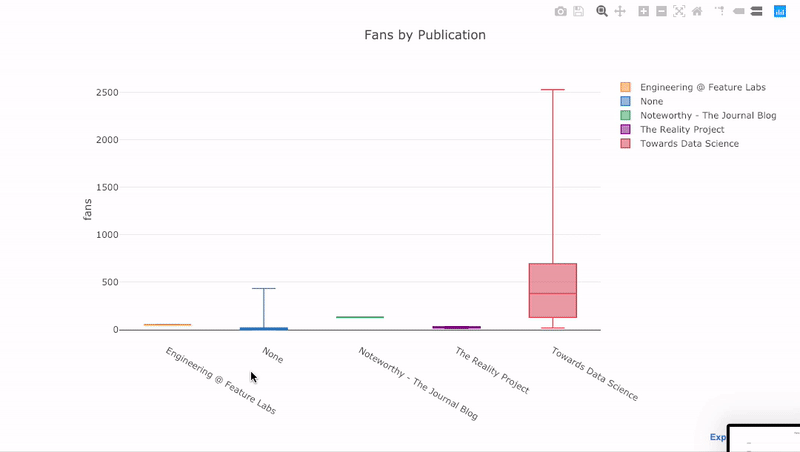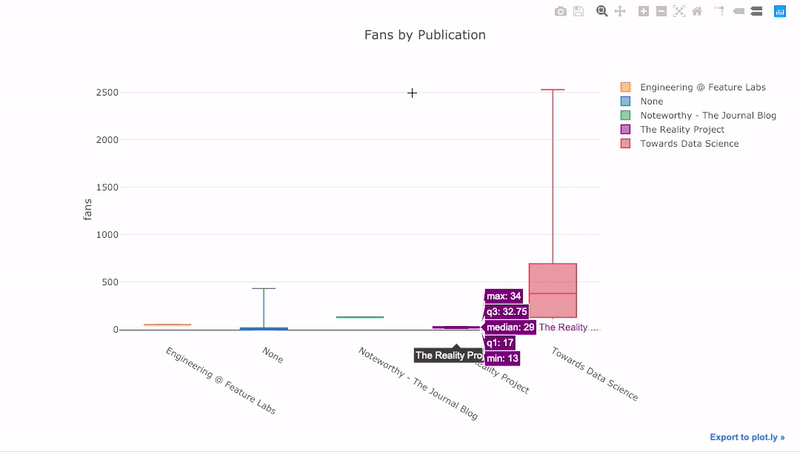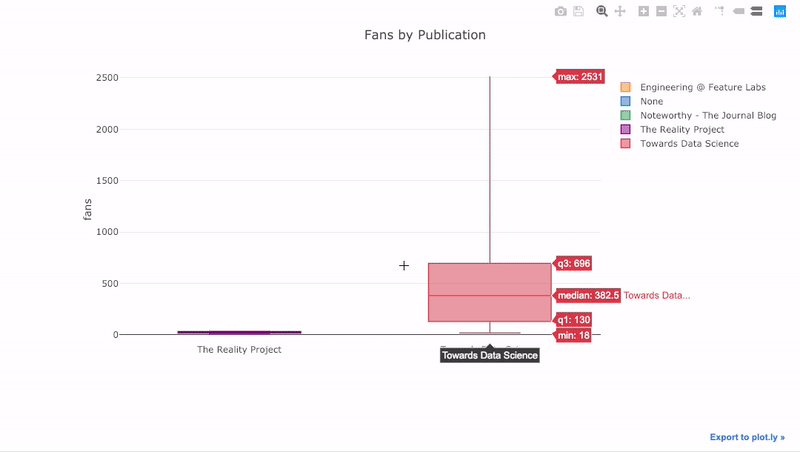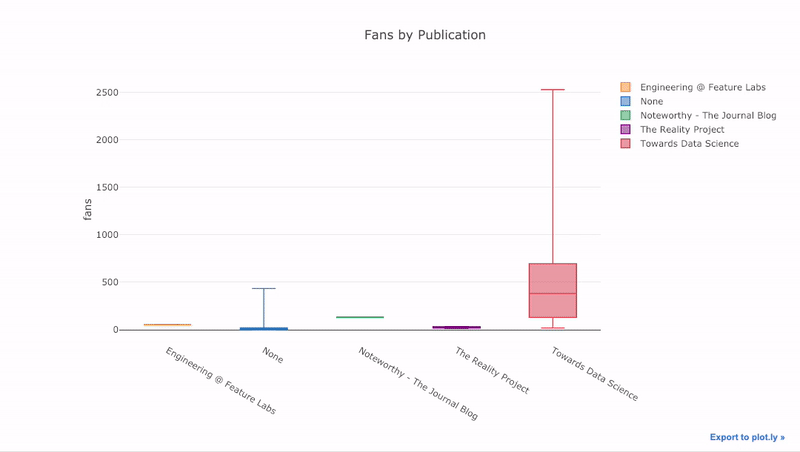
Die Vorteile der Interaktivität bestehen darin, dass wir die Daten nach Belieben untersuchen und hosten können. Das Boxfloß enthält viele Informationen, und ohne die Möglichkeit, die Zahlen zu sehen, werden wir das meiste davon vermissen!
Streudiagramm
Das Streudiagramm ist das Herzstück der meisten Analysen. Auf diese Weise können wir die zeitliche Entwicklung einer Variablen oder die Beziehung zwischen zwei (oder mehr) Variablen sehen.
Zeitfolgen
Ein Großteil der realen Daten hat ein Zeitelement. Glücklicherweise wurde Plotly + Manschettenknöpfe mit Blick auf die Zeitreihenvisualisierung entworfen. Lassen Sie uns die Daten aus meinen TDS-Artikeln einrahmen und sehen, wie sich die Trends geändert haben.
Create a dataframe of Towards Data Science Articles
tds = df[df['publication'] == 'Towards Data Science'].\
set_index('published_date')
# Plot read time as a time series
tds[['claps', 'fans', 'title']].iplot(
y='claps', mode='lines+markers', secondary_y = 'fans',
secondary_y_title='Fans', xTitle='Date', yTitle='Claps',
text='title', title='Fans and Claps over Time')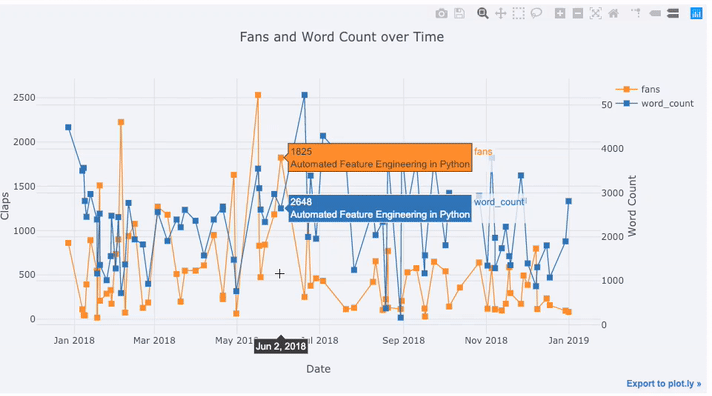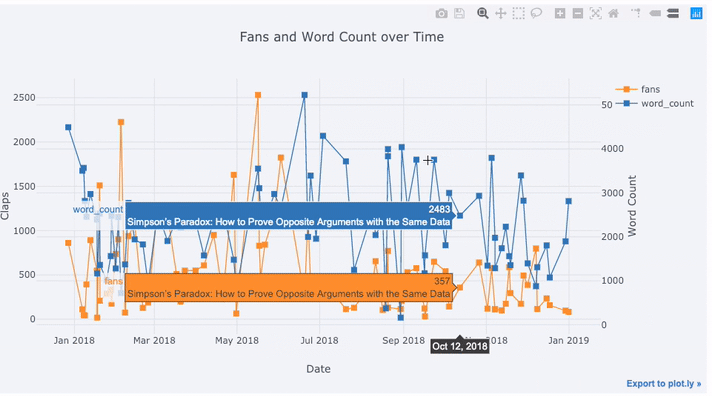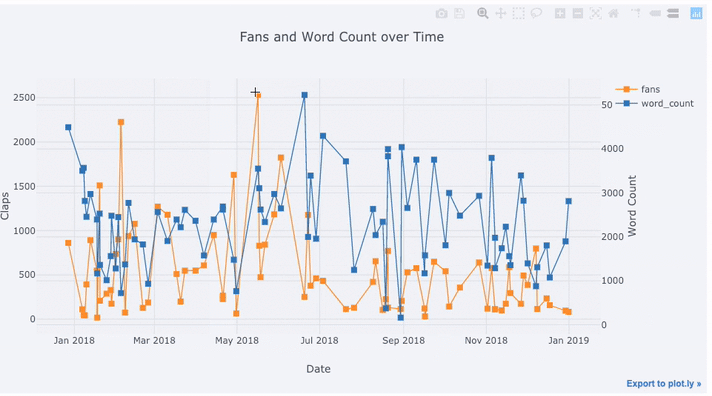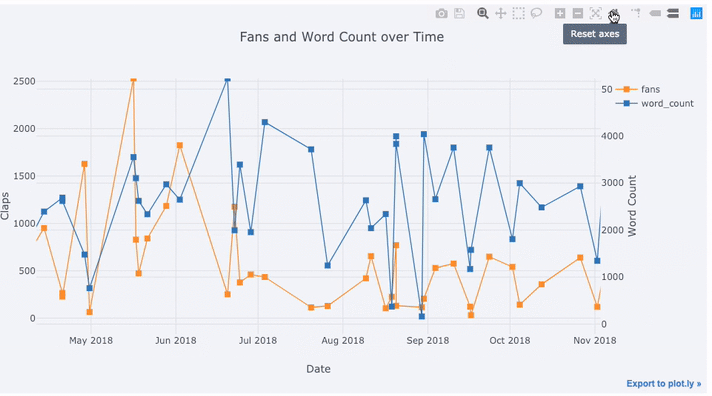
Wir sehen hier einige verschiedene Dinge:
- Erhalten Sie automatisch schön formatierte Zeitreihen auf der x-Achse
- Hinzufügen einer sekundären y-Achse, da unsere Variablen unterschiedliche Bereiche haben
- Anzeigen von Artikeltiteln beim Hover
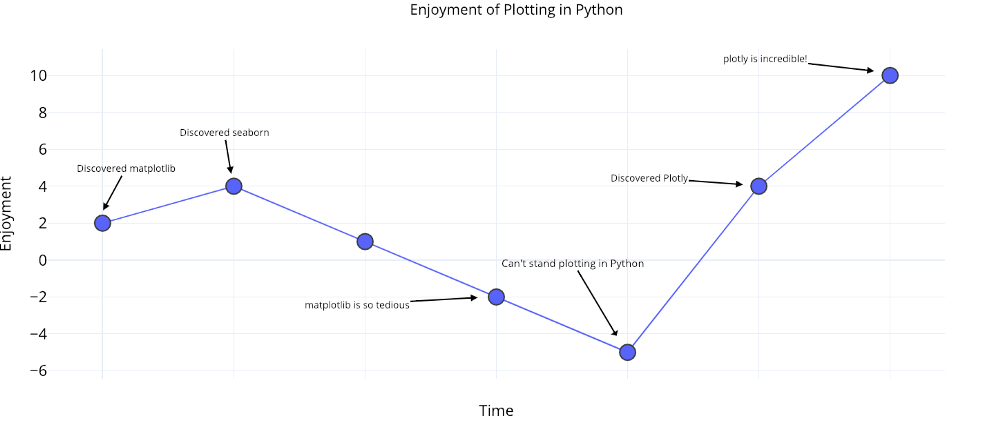
Für weitere Informationen können wir auch ganz einfach Textanmerkungen hinzufügen:
tds_monthly_totals.iplot(
mode='lines+markers+text',
text=text,
y='word_count',
opacity=0.8,
xTitle='Date',
yTitle='Word Count',
title='Total Word Count by Month')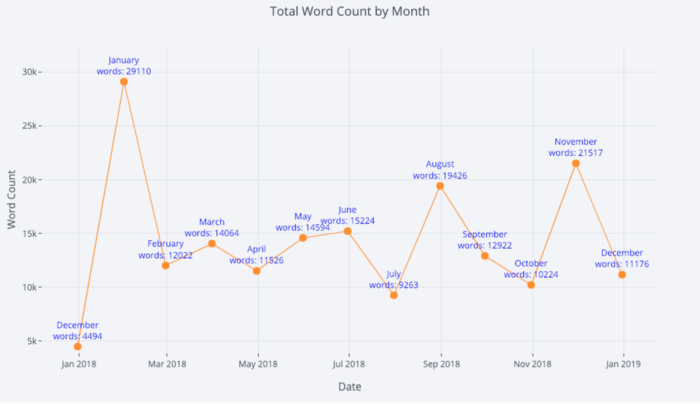
Für ein Streudiagramm mit zwei Variablen, das mit der dritten kategorialen Variablen gefärbt ist, verwenden wir:
df.iplot(
x='read_time',
y='read_ratio',
# Specify the category
categories='publication',
xTitle='Read Time',
yTitle='Reading Percent',
title='Reading Percent vs Read Ratio by Publication')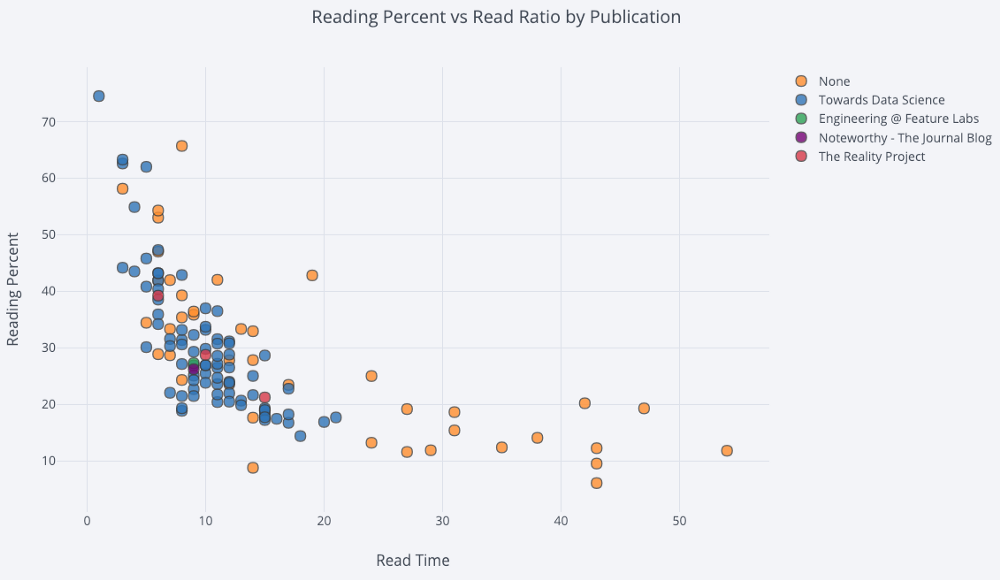
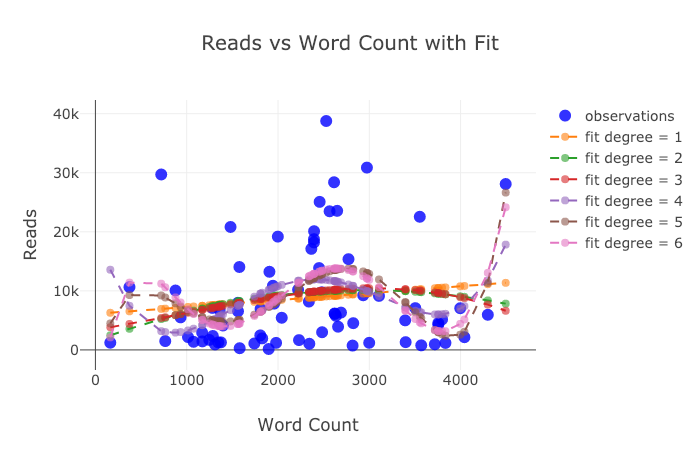
Lassen Sie uns die Dinge etwas komplizieren, indem wir eine Protokollachse verwenden, die als Plotlayout angegeben ist (Layoutspezifikationen finden Sie in der Plotly-Dokumentation ) und die Größe der Blasen einer numerischen Variablen definieren:
tds.iplot(
x='word_count',
y='reads',
size='read_ratio',
text=text,
mode='markers',
# Log xaxis
layout=dict(
xaxis=dict(type='log', title='Word Count'),
yaxis=dict(title='Reads'),
title='Reads vs Log Word Count Sized by Read Ratio'))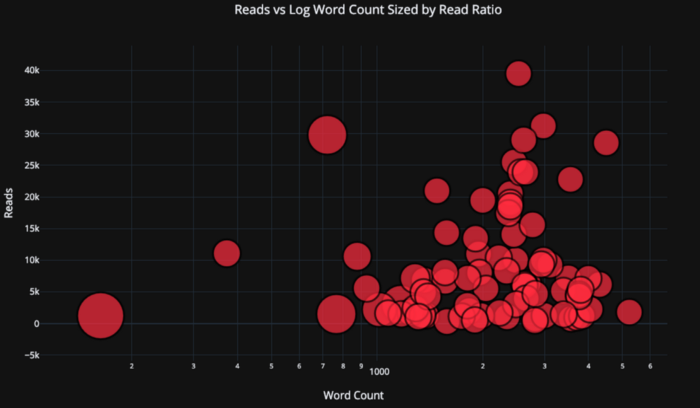
Mit ein wenig Arbeit ( Details siehe NoteBook ) können wir sogar vier Variablen ( nicht empfohlen ) in ein Diagramm einfügen !
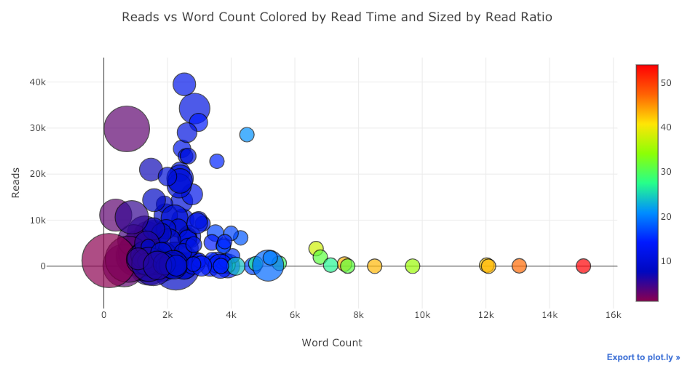
Nach wie vor können wir Pandas mit Plot + Manschettenknöpfen kombinieren, um nützliche Grafiken zu erhalten
df.pivot_table(
values='views', index='published_date',
columns='publication').cumsum().iplot(
mode='markers+lines',
size=8,
symbol=[1, 2, 3, 4, 5],
layout=dict(
xaxis=dict(title='Date'),
yaxis=dict(type='log', title='Total Views'),
title='Total Views over Time by Publication'))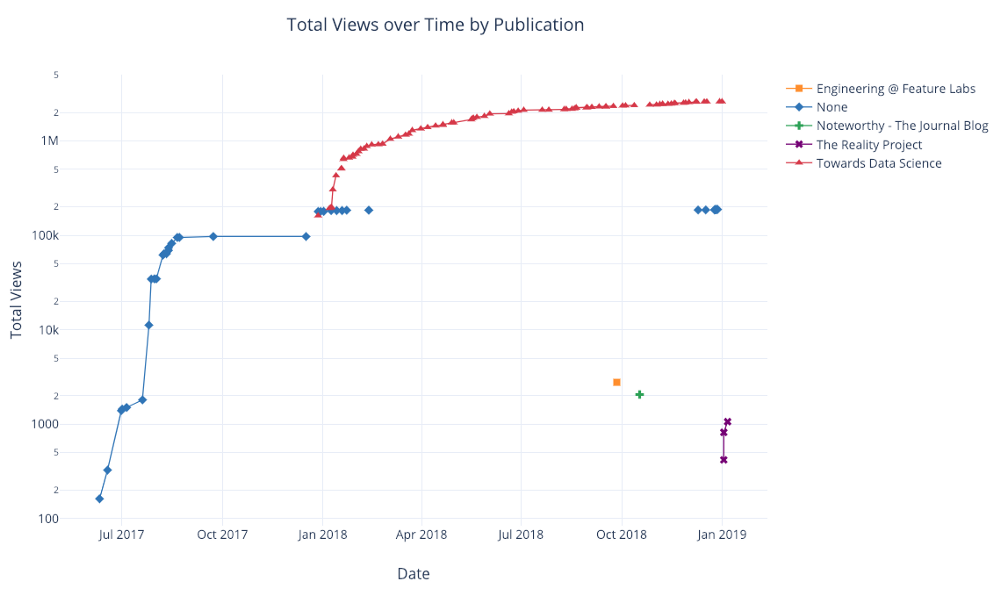
Weitere Funktionsbeispiele finden Sie im Notizbuch oder in der Dokumentation . Wir können unseren Diagrammen mit einer Codezeile und dennoch mit allen Interaktionen Textanmerkungen, Referenzlinien und Best-Fit-Linien hinzufügen.
Erweiterte Diagramme
Wir gehen nun zu einigen Grafiken über, die Sie wahrscheinlich nicht so oft verwenden werden, die aber sehr beeindruckend sein können. Wir werden plotly figure_factory verwenden , um selbst diese unglaublichen Haffics in einer Zeile zu erstellen.
Streumatrix
Wenn wir die Beziehungen zwischen vielen Variablen untersuchen möchten, ist die Streumatrix (auch Splom genannt) eine großartige Option:
import plotly.figure_factory as ff
figure = ff.create_scatterplotmatrix(
df[['claps', 'publication', 'views',
'read_ratio','word_count']],
diag='histogram',
index='publication')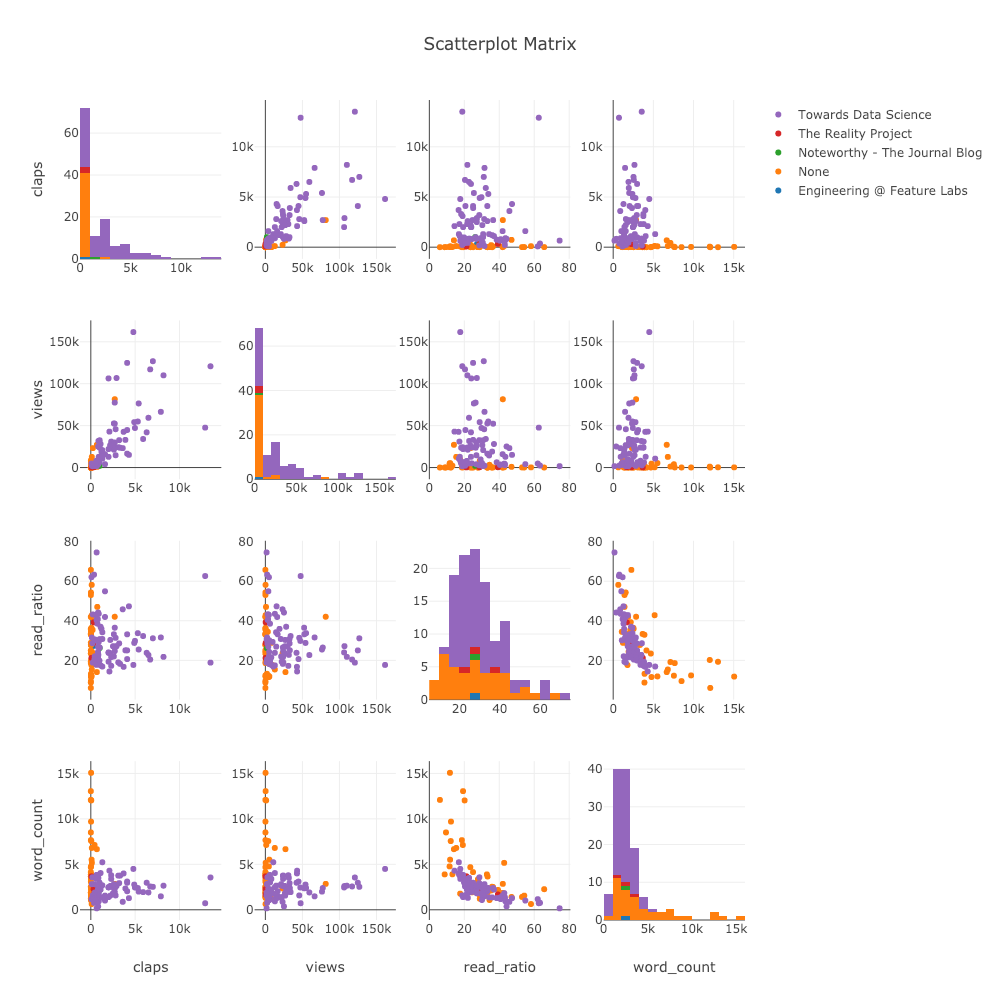
Auch dieses Diagramm ist vollständig interaktiv, sodass wir die Daten untersuchen können.
Korrelationswärmekarte
Um Korrelationen zwischen numerischen Variablen zu visualisieren, berechnen wir die Korrelationen und erstellen dann eine kommentierte Heatmap:
corrs = df.corr()
figure = ff.create_annotated_heatmap(
z=corrs.values,
x=list(corrs.columns),
y=list(corrs.index),
annotation_text=corrs.round(2).values,
showscale=True)
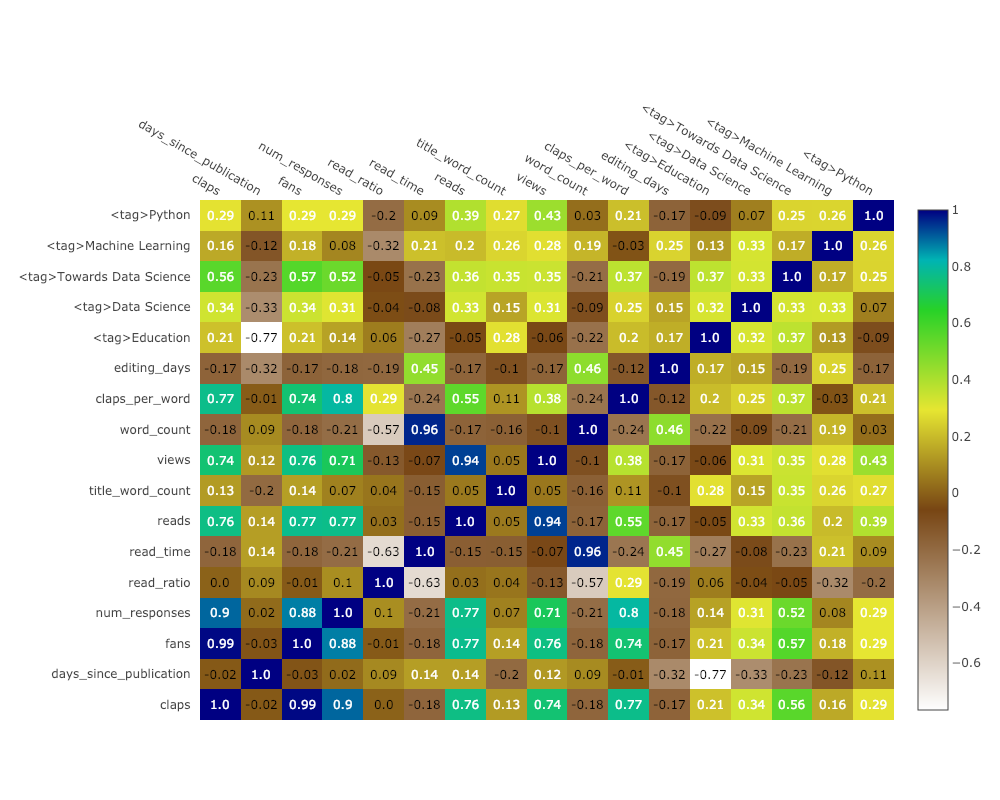
Die Liste der Grafiken geht weiter und weiter. Manschettenknöpfe haben auch verschiedene Themen, mit denen wir mühelos ein völlig anderes Erscheinungsbild erhalten können. Im Folgenden finden Sie beispielsweise ein Verhältnisdiagramm im Thema "Raum" und ein Streudiagramm in "ggplot":
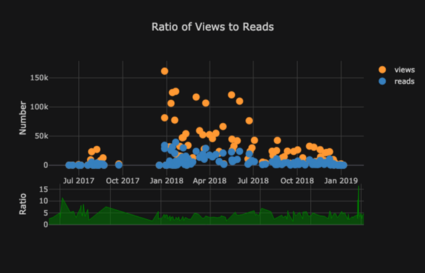
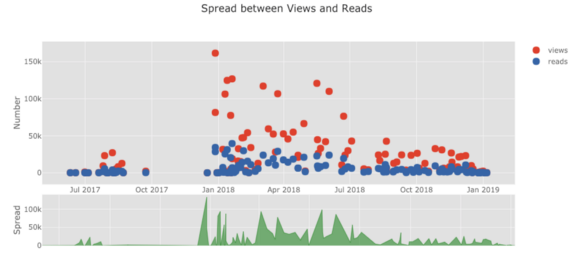
Wir erhalten auch 3D-Diagramme (Oberflächen- und Blasendiagramme):
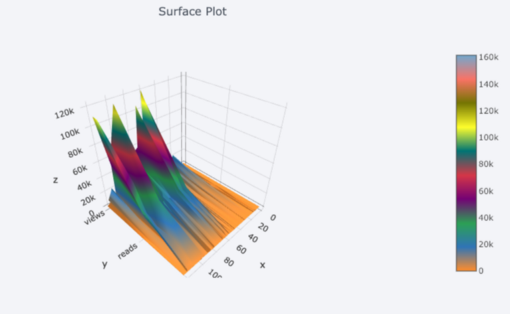
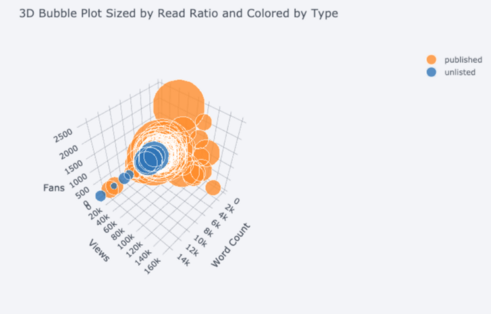
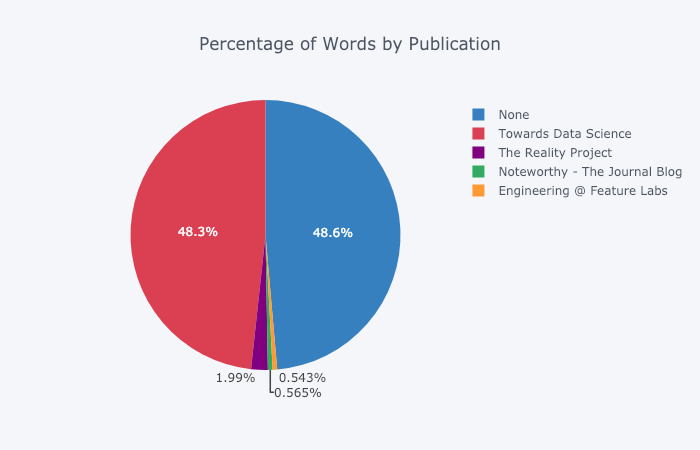
Für diejenigen, die möchten , können Sie sogar ein Kreisdiagramm erstellen:
Bearbeiten in Plotly Chart Studio
Wenn Sie diese Diagramme in NoteBook Jupiter erstellen, sehen Sie einen kleinen Link in der unteren rechten Ecke des Diagramms „In plot.ly exportieren“. Wenn Sie auf diesen Link klicken, werden Sie zu Chart Studio weitergeleitet, wo Sie Ihr Diagramm für die endgültige Präsentation optimieren können. Sie können Anmerkungen hinzufügen, Farben angeben und im Allgemeinen alles für ein großartiges Diagramm löschen. Anschließend können Sie Ihren Zeitplan im Internet veröffentlichen, sodass jeder ihn anhand der Referenz finden kann.
Im Folgenden sind zwei Diagramme aufgeführt, die ich in Chart Studio optimiert habe:
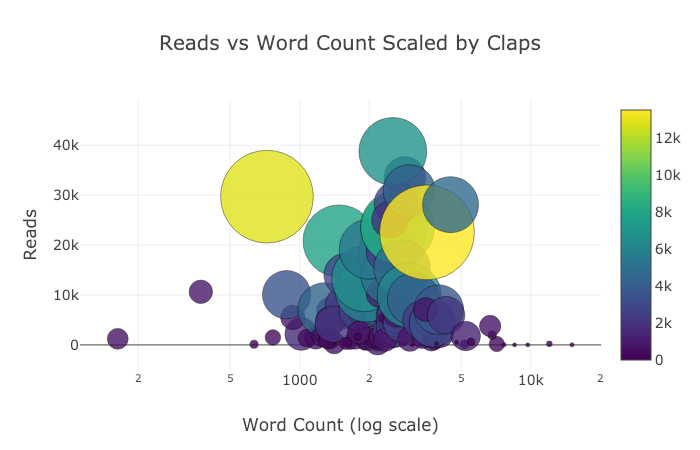
Trotz allem, was hier gesagt wurde, haben wir noch nicht alle Funktionen der Bibliothek untersucht! Ich würde vorschlagen, dass Sie sich sowohl die Plotdokumentation als auch die Manschettenknopfdokumentation ansehen, um weitere unglaubliche Plots zu erhalten.
Schlussfolgerungen
Das Schlimmste an dem unterbewerteten Missverständnis ist, dass Sie erst erkennen, wie viel Zeit Sie nach dem Beenden verschwendet haben. Zum Glück müssen Sie jetzt, da ich den Fehler gemacht habe, zu lange bei matploblib zu bleiben, nicht mehr!
Wenn wir über Plotbibliotheken nachdenken, gibt es mehrere Dinge, die wir wollen:
- Einzeilige Diagramme zur schnellen Erkundung
- Interaktive Datenersetzung / -exploration
- Die Fähigkeit, nach Bedarf in Details zu graben
- Einfache Einrichtung für die endgültige Präsentation
Im Moment ist die beste Option, um all dies in Python zu tun, die Handlung. Mit Plotly können wir schnell Visualisierungen erstellen und unsere Daten durch Interaktivität besser verstehen. Seien wir ehrlich, Charting muss einer der schönsten Teile der Datenwissenschaft sein! Bei anderen Bibliotheken hat sich das Plotten zu einer mühsamen Aufgabe entwickelt, aber beim Plotten gibt es die Freude, wieder eine großartige Figur zu machen!

In den kostenpflichtigen Online-Kursen von SkillFactory erfahren Sie, wie Sie einen hochkarätigen Beruf von Grund auf neu aufbauen oder Ihre Fähigkeiten und Ihr Gehalt verbessern können:
- Ausbildung des Data Science-Berufs von Grund auf (12 Monate)
- Analytics-Beruf mit jedem Startlevel (9 Monate)
- Kurs für maschinelles Lernen (12 Wochen)
- «Python -» (9 )
- DevOps (12 )
- - (8 )