
Hier finden Sie eine Liste der im Juni veröffentlichten Materialien in englischer Sprache. Alle von ihnen sind ohne übermäßigen Akademismus geschrieben, enthalten Codebeispiele und Links zu nicht leeren Repositories. Die meisten der genannten Technologien sind gemeinfrei und erfordern zum Testen keine Hochleistungshardware.
Image GPT
Open AI hat entschieden, dass ein auf Text trainiertes Transformatormodell kohärente vollständige Sätze erzeugen kann. Wenn das Modell auf Pixelsequenzen trainiert wird, kann es erweiterte Bilder erzeugen. Open AI zeigt, wie eine qualitativ hochwertige Abtastung und eine genaue Bildklassifizierung es dem generierten Modell ermöglichen, mit den besten Faltungsmodellen in unbeaufsichtigten Lernumgebungen zu konkurrieren.

Face Depixelizer
Vor einem Monat hatten wir die Gelegenheit, mit dem Tool zu spielen, das ein Modell des maschinellen Lernens verwendet, um Porträts in wunderschöne Pixelkunst umzuwandeln. Es macht Spaß, aber es ist schwer vorstellbar, dass diese Technologie noch weit verbreitet ist. Das Werkzeug, das den gegenteiligen Effekt erzeugt, interessierte sich jedoch sofort für die Öffentlichkeit. Mit Hilfe eines Gesichtsdepixelisierers wird es theoretisch möglich sein, die Identität einer Person durch Videoaufzeichnung von Überwachungskameras festzustellen.

DeepFaceDrawing
Wenn die Arbeit mit Pixelbildern nicht ausreicht und Sie ein Foto mit einem Porträt einer Person aus einer primitiven Skizze erstellen müssen, ist hierfür bereits ein auf DNN basierendes Tool erschienen. Wie von den Machern konzipiert, werden nur allgemeine Umrisse benötigt und keine professionellen Skizzen. Das Modell stellt dann selbst das Gesicht der Person wieder her, was mit der Skizze übereinstimmt. Das System wurde mit dem Jittor-Framework erstellt. Wie die Entwickler versprechen, wird der Quellcode für Pytorch demnächst zum Projekt-Repository hinzugefügt.
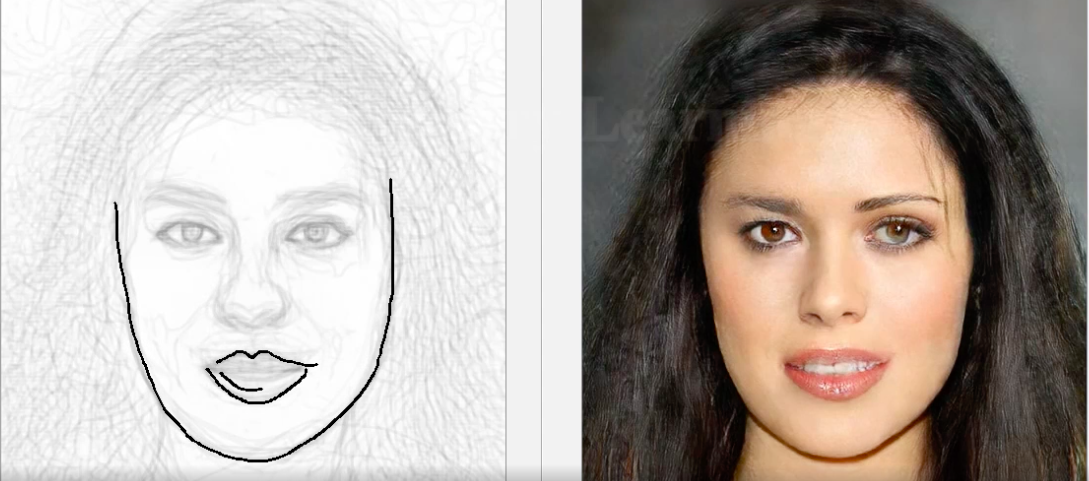
PIFuHD
Was ist mit dem Rest des Körpers, wenn die Gesichtsrekonstruktionen aussortiert sind? Dank der Entwicklung von DNN wurde es möglich, eine menschliche Figur anhand eines zweidimensionalen Fotos in 3D zu modellieren. Die Hauptbeschränkung war auf die Tatsache zurückzuführen, dass genaue Vorhersagen die Analyse eines breiteren Kontexts und von Quelldaten in hoher Auflösung erfordern. Die mehrschichtige Architektur und die End-to-End-Lernfunktionen des Modells helfen bei der Lösung dieses Problems. Um Ressourcen zu sparen, wird auf der ersten Ebene das gesamte Bild in niedriger Auflösung analysiert. Der Kontext wird dann gebildet, und auf einer detaillierteren Ebene bewertet das Modell die Geometrie durch Analyse des hochauflösenden Bildes.

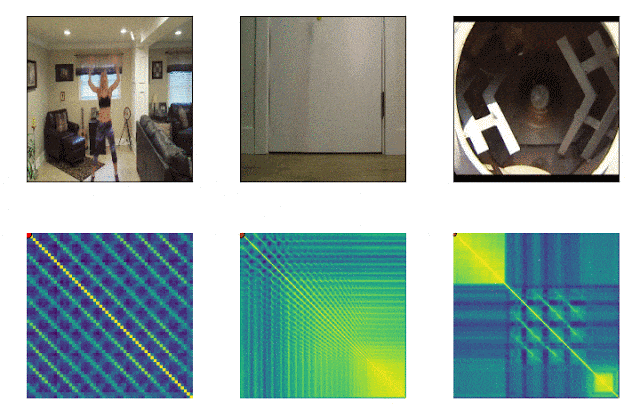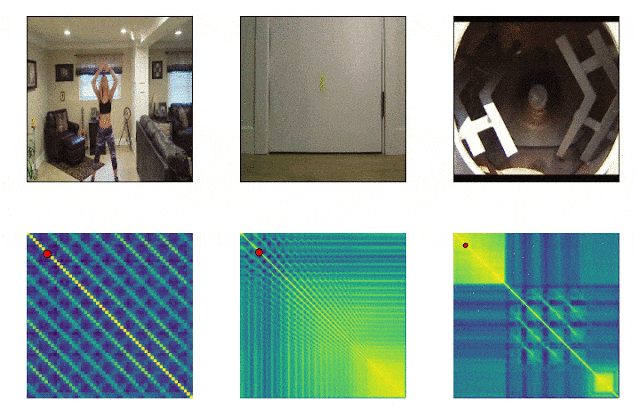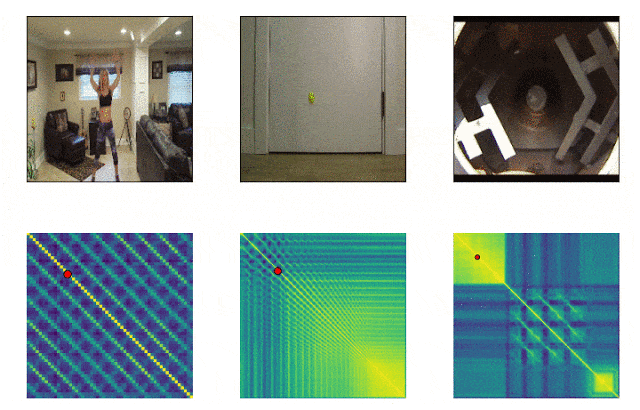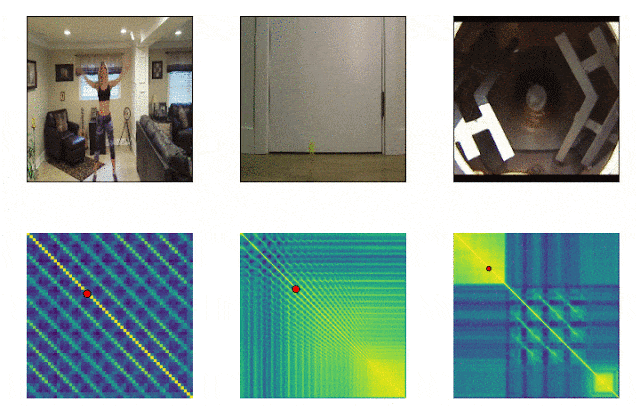
RepNet
Viele Dinge, die uns umgeben, bestehen aus Zyklen unterschiedlicher Frequenz. Um das Wesen eines Phänomens zu verstehen, ist es häufig erforderlich, Informationen über seine wiederkehrenden Manifestationen zu analysieren. Unter Berücksichtigung der Möglichkeiten der Videoaufnahme ist es nicht mehr schwierig, die Wiederholungen zu beheben, sondern bestand darin, sie zu zählen. Die Methode des Einzelbildvergleichs der Pixeldichte in einem Bild war häufig aufgrund von Verwacklungen der Kamera oder Verstopfung durch Objekte sowie eines starken Unterschieds in Maßstab und Form beim Vergrößern und Verkleinern nicht geeignet. Ein von Google entwickeltes Modell löst dieses Problem. Es identifiziert sich wiederholende Aktionen im Video, einschließlich solcher, die nicht im Training verwendet wurden. Infolgedessen gibt das Modell Daten zur Häufigkeit wiederholter Aktionen zurück, die im Video erkannt wurden. Colab ist bereits verfügbar .
SPICE-Modell
Bisher mussten Sie sich auf ausgefeilte Signalverarbeitungsalgorithmen verlassen, um die Tonhöhe zu bestimmen. Die größte Herausforderung bestand darin, den untersuchten Klang von Hintergrundgeräuschen oder dem Klang von Begleitinstrumenten zu trennen. Für diese Aufgabe steht jetzt ein vorab trainiertes Modell zur Verfügung, das hohe und niedrige Frequenzen erkennt. Das Modell kann im Internet und auf Mobilgeräten verwendet werden.
Sozialer Distanzierungsdetektor
Der Fall, ein Programm zu erstellen, mit dem Sie verfolgen können, ob Menschen soziale Distanzierung beobachten. Der Autor erzählt ausführlich, wie er ein vorab trainiertes Modell ausgewählt hat, wie er mit der Aufgabe des Erkennens von Personen fertig wurde und wie er mit OpenCV das Bild in eine orthografische Projektion umwandelte, um den Abstand zwischen Personen zu berechnen. Sie können sich auch mit dem Quellcode des Projekts vertraut machen .

Erkennung typischer Dokumente
Heutzutage gibt es Tausende von Variationen der gängigsten Vorlagendokumente wie Quittungen, Rechnungen und Schecks. Bestehende automatisierte Systeme, die für die Verwendung mit einem sehr begrenzten Vorlagentyp ausgelegt sind. Google schlägt vor, dafür maschinelles Lernen zu verwenden. Der Artikel beschreibt die Architektur des Modells und die Ergebnisse der erhaltenen Daten. Das Tool wird bald Teil des Document AI- Dienstes .
Erstellen einer skalierbaren Pipeline für die Entwicklung und Bereitstellung von Algorithmen für maschinelles Lernen für den kontaktlosen Einzelhandel
Das israelische Startup Trigo teilt seine Erfahrungen mit dem Einsatz von maschinellem Lernen und Computer Vision für den Einzelhandel zum Mitnehmen. Das Unternehmen ist Anbieter eines Systems, mit dem Geschäfte ohne Registrierkasse betrieben werden können. Die Autoren erläutern, mit welchen Aufgaben sie konfrontiert waren, und erklären, warum sie PyTorch als Framework für maschinelles Lernen und Allegro AI Trains für die Infrastruktur ausgewählt haben und wie sie den Entwicklungsprozess etabliert haben.
Das ist alles, danke für Ihre Aufmerksamkeit!