In X5 heißt das System, das etikettierte Waren verfolgt und Daten mit der Regierung und den Lieferanten austauscht, „Markus“. Lassen Sie uns sagen, wie und wer es entwickelt hat, welche Art von Technologie-Stack es hat und warum wir etwas haben, auf das wir stolz sein können.
Echtes HighLoad
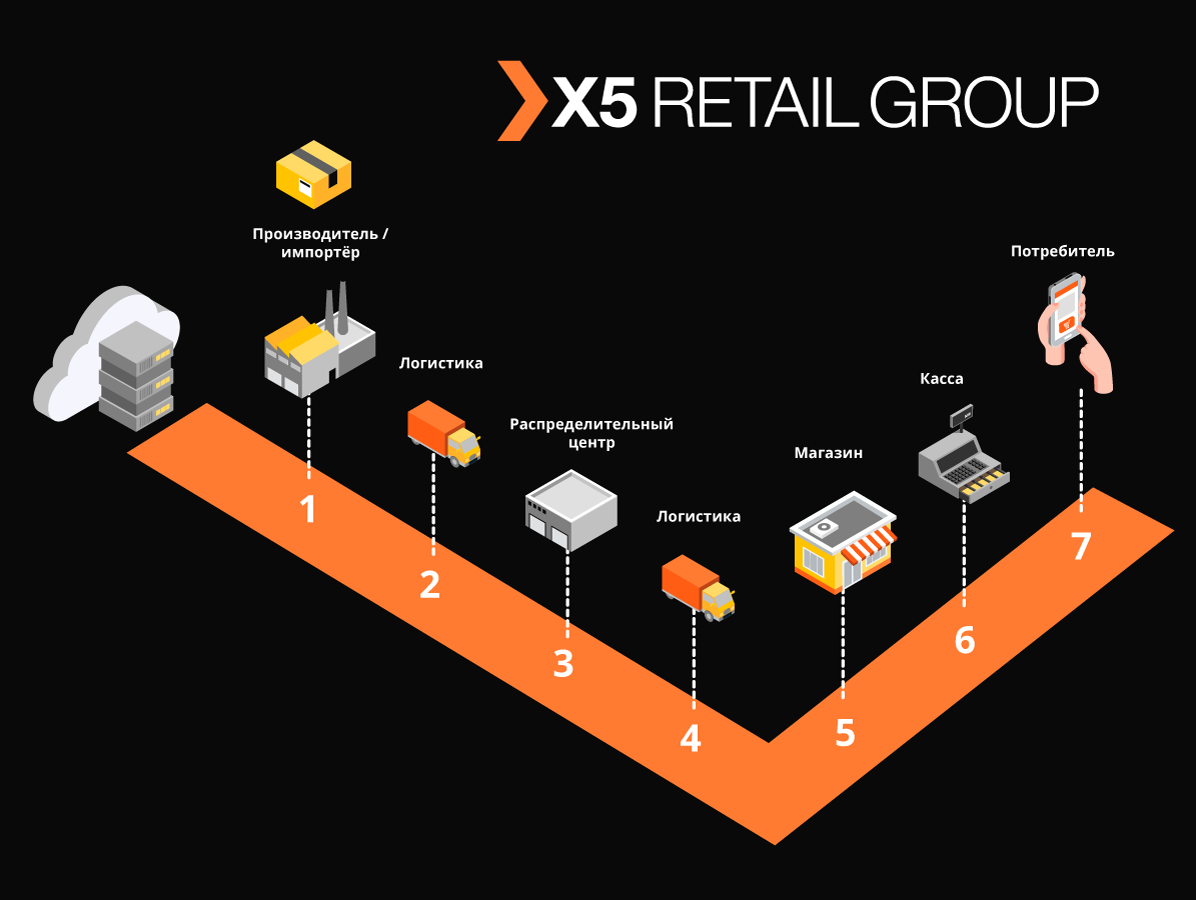
„Markus“ löst viele Probleme. Das Hauptproblem ist die Integrationsinteraktion zwischen den Informationssystemen X5 und dem staatlichen Informationssystem für gekennzeichnete Produkte (GIS MP) zur Verfolgung der Bewegung gekennzeichneter Produkte. Die Plattform speichert auch alle Markierungscodes, die wir erhalten haben, und die gesamte Historie der Bewegung dieser Codes über Objekte hinweg hilft, das erneute Sortieren markierter Produkte zu vermeiden. Am Beispiel von Tabakerzeugnissen, die in den ersten Gruppen etikettierter Waren enthalten waren, enthält nur ein Zigarettenwagen etwa 600.000 Packungen, von denen jede einen eigenen Code hat. Die Aufgabe unseres Systems besteht darin, die Rechtmäßigkeit der Bewegungen jeder solchen Packung zwischen Lagern und Filialen zu verfolgen und zu überprüfen und letztendlich die Zulässigkeit ihrer Implementierung für den Endkunden zu überprüfen. Und wir verzeichnen Bargeldtransaktionen von ungefähr 125.000 pro Stunde.und es ist auch notwendig aufzuzeichnen, wie jede solche Packung in den Laden kam. Unter Berücksichtigung aller Bewegungen zwischen Objekten erwarten wir daher zig Milliarden Datensätze pro Jahr.
Team M.
Trotz der Tatsache, dass "Markus" als Projekt innerhalb des X5 betrachtet wird, wird es gemäß dem Produktansatz implementiert. Das Team arbeitet an Scrum. Der Start des Projekts war im letzten Sommer, aber die ersten Ergebnisse kamen erst im Oktober - das eigene Team wurde vollständig zusammengestellt, die Systemarchitektur wurde entwickelt und die Ausrüstung wurde gekauft. Jetzt hat das Team 16 Mitarbeiter, von denen sechs an der Entwicklung von Backend und Frontend beteiligt sind, drei an der Systemanalyse. Sechs weitere Personen sind an manuellen, Lade-, automatisierten Tests und Produktunterstützungen beteiligt. Zusätzlich haben wir einen SRE-Spezialisten.
Der Code in unserem Team wird nicht nur von Entwicklern geschrieben, fast alle wissen, wie man Autotests programmiert und schreibt, Skripte lädt und Skripte automatisiert. Besonderes Augenmerk legen wir darauf, da auch die Produktunterstützung einen hohen Automatisierungsgrad erfordert. Wir versuchen immer, unsere Kollegen, die noch nicht programmiert haben, zu beraten und ihnen zu helfen, einige kleine Aufgaben zu erledigen.
Im Zusammenhang mit der Coronavirus-Pandemie haben wir das gesamte Team auf Remote-Arbeit übertragen. Die Verfügbarkeit aller Entwicklungsmanagement-Tools, der in Jira und GitLab erstellte Workflow haben es einfach gemacht, diese Phase zu durchlaufen. Die Monate an einem abgelegenen Ort haben gezeigt, dass die Produktivität des Teams nicht darunter gelitten hat. Für viele hat sich der Arbeitskomfort erhöht. Das einzige ist, dass nicht genügend Live-Kommunikation vorhanden ist.
Teambesprechung vor der Distanz

Remote-Meetings
Lösungstechnologie-Stack
Das Standard-Repository und CI / CD-Tool für X5 ist GitLab. Wir verwenden es für die Codespeicherung, kontinuierliche Tests, Bereitstellung auf Test- und Produktionsservern. Wir verwenden auch die Praxis der Codeüberprüfung, wenn mindestens zwei Kollegen die vom Entwickler am Code vorgenommenen Änderungen genehmigen müssen. Die statischen Codeanalysatoren SonarQube und JaCoCo helfen uns, den Code sauber zu halten und die erforderliche Abdeckung für Unit-Tests bereitzustellen. Alle Änderungen im Code müssen diese Überprüfungen durchlaufen. Alle manuell ausgeführten Testskripte werden anschließend automatisiert.
Für die erfolgreiche Ausführung von Geschäftsprozessen durch „Markus“ mussten wir eine Reihe von technologischen Problemen in der richtigen Reihenfolge lösen.
Aufgabe 1. Die Notwendigkeit einer horizontalen Skalierbarkeit des Systems
Um dieses Problem zu lösen, haben wir einen Microservice-Ansatz für die Architektur gewählt. Gleichzeitig war es sehr wichtig, die Verantwortungsbereiche der Dienstleistungen zu verstehen. Wir haben versucht, sie unter Berücksichtigung der Besonderheiten der Prozesse in Geschäftsabläufe zu unterteilen. Beispielsweise ist die Annahme in einem Lager nicht sehr häufig, sondern ein sehr umfangreicher Vorgang, bei dem es erforderlich ist, von der staatlichen Regulierungsbehörde so schnell wie möglich Informationen über die eingegangenen Wareneinheiten zu erhalten, deren Anzahl in einer Lieferung 600.000 erreicht, die Zulässigkeit der Annahme dieses Produkts in das Lager zu prüfen und alles zu geben notwendige Informationen für das Lagerautomatisierungssystem. Der Versand aus Lagern hat jedoch eine viel höhere Intensität, arbeitet aber gleichzeitig mit kleinen Datenmengen.
Wir implementieren alle Dienste nach dem staatenlosen Prinzip und versuchen sogar, interne Vorgänge in Schritte zu unterteilen, indem wir sogenannte Kafka-Selbstthemen verwenden. In diesem Fall sendet ein Microservice eine Nachricht an sich selbst, die es ermöglicht, die Last für ressourcenintensivere Vorgänge auszugleichen und die Produktwartung zu vereinfachen, aber dazu später mehr.
Wir haben beschlossen, Module für die Interaktion mit externen Systemen in separate Dienste zu unterteilen. Dies ermöglichte es, das Problem häufig wechselnder APIs externer Systeme zu lösen, ohne dass dies Auswirkungen auf Dienste mit Geschäftsfunktionalität hatte.
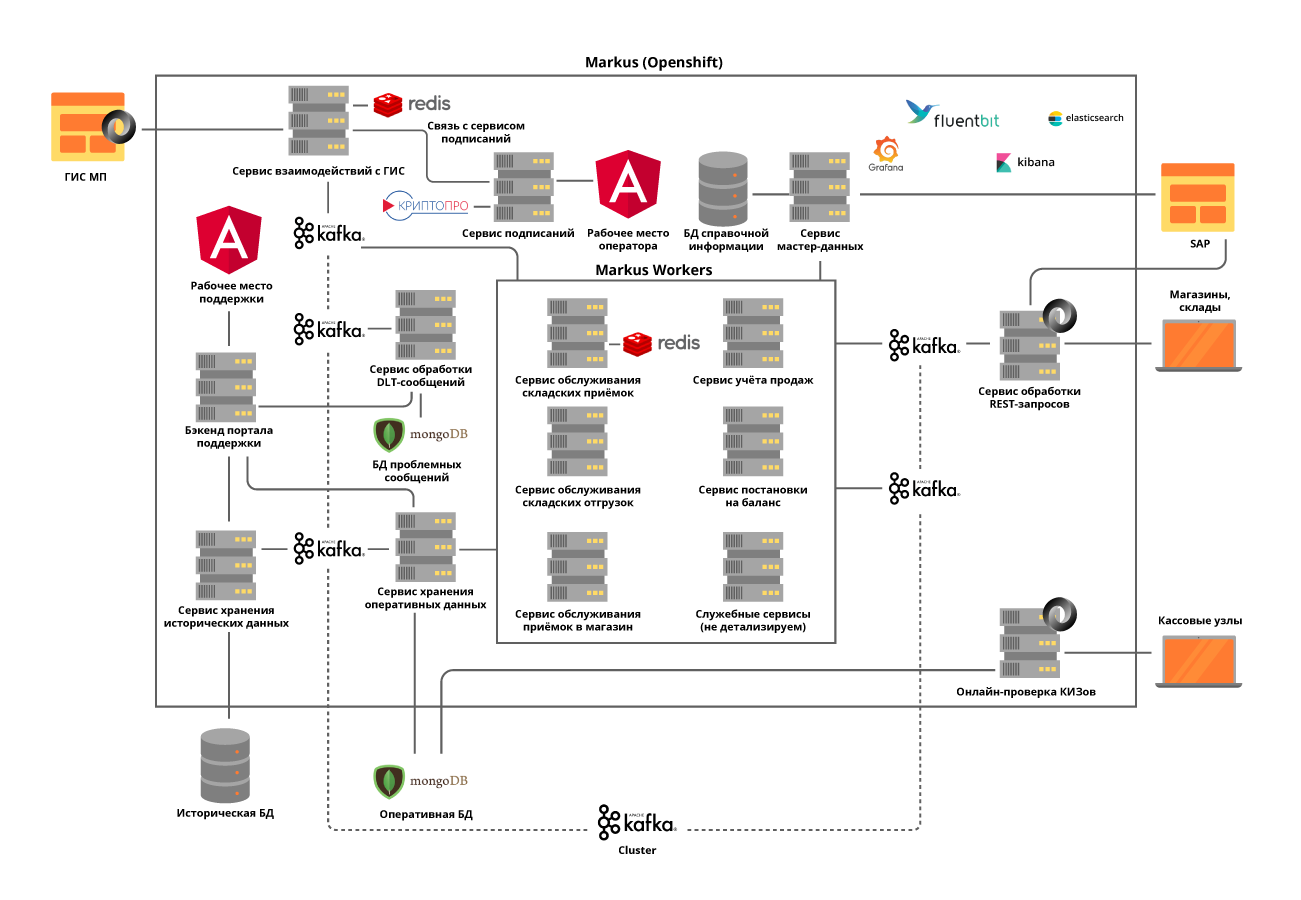
Alle Microservices werden im OpenShift-Cluster bereitgestellt. Dies löst sowohl das Problem der Skalierung jedes Microservices als auch die Verwendung von Service Discovery-Tools von Drittanbietern.
Aufgabe 2. Die Notwendigkeit einer hohen Last und eines sehr intensiven Datenaustauschs zwischen Plattformdiensten: Nur in der Projektstartphase werden etwa 600 Operationen pro Sekunde ausgeführt. Wir erwarten, dass dieser Wert auf bis zu 5000 op / sec steigt, wenn Handelsobjekte mit unserer Plattform verbunden werden.
Diese Aufgabe wurde gelöst, indem ein Kafka-Cluster bereitgestellt und die synchrone Kommunikation zwischen Plattform-Microservices fast vollständig aufgegeben wurde. Dies erfordert eine sehr sorgfältige Analyse der Systemanforderungen, da nicht alle Vorgänge asynchron sein können. Gleichzeitig übertragen wir nicht nur Ereignisse über den Broker, sondern auch alle erforderlichen Geschäftsinformationen in der Nachricht. Somit kann die Nachrichtengröße bis zu mehreren hundert Kilobyte betragen. Um das Nachrichtenvolumen in Kafka zu begrenzen, müssen wir die Größe der Nachrichten genau vorhersagen und sie gegebenenfalls aufteilen. Die Aufteilung ist jedoch logisch und mit dem Geschäftsbetrieb verbunden.
Zum Beispiel, wenn die Ware im Auto angekommen ist, teilen wir sie in Kisten. Für den synchronen Betrieb werden separate Mikrodienste zugewiesen und strenge Belastungstests durchgeführt. Die Verwendung von Kafka stellte uns vor eine weitere Herausforderung: Durch das Testen unseres Service mit Kafka-Integration werden alle unsere Komponententests asynchron. Wir haben dieses Problem gelöst, indem wir unsere eigenen nützlichen Methoden mit dem Embedded Kafka Broker geschrieben haben. Dies macht das Schreiben von Komponententests für einzelne Methoden nicht überflüssig, wir ziehen es jedoch vor, komplexe Fälle mit Kafka zu testen.
Wir haben der Verfolgung von Protokollen große Aufmerksamkeit gewidmet, damit ihre TraceId nicht verloren geht, wenn während des Betriebs von Diensten oder bei der Arbeit mit Kafka-Batch Ausnahmen ausgelöst werden. Und wenn es bei der ersten keine speziellen Fragen gab, müssen wir im zweiten Fall die gesamte TraceId, mit der der Stapel geliefert wurde, in das Protokoll schreiben und eine auswählen, um die Ablaufverfolgung fortzusetzen. Wenn der Benutzer dann nach der anfänglichen TraceId sucht, kann er leicht herausfinden, mit welcher Ablaufverfolgung die Ablaufverfolgung fortgesetzt wurde.
Ziel 3. Notwendigkeit, eine große Datenmenge zu speichern: Allein für Tabak werden jährlich mehr als 1 Milliarde Etiketten für Tabak an X5 gesendet. Sie erfordern einen ständigen und schnellen Zugriff. Insgesamt muss das System etwa 10 Milliarden Aufzeichnungen über die Geschichte des Transports dieser markierten Waren verarbeiten.
Um das dritte Problem zu lösen, wurde die MongoDB NoSQL-Datenbank ausgewählt. Wir haben einen Shard mit 5 Knoten und in jedem Knoten einen Replikatsatz mit 3 Servern erstellt. Auf diese Weise können Sie das System horizontal skalieren, dem Cluster neue Server hinzufügen und dessen Fehlertoleranz sicherstellen. Hier standen wir vor einem weiteren Problem - der Sicherstellung der Transaktionsfähigkeit im Mongo-Cluster unter Berücksichtigung der Verwendung horizontal skalierbarer Mikrodienste. Eine der Aufgaben unseres Systems besteht beispielsweise darin, Versuche zu erkennen, Waren mit denselben Markierungscodes weiterzuverkaufen. Hier treten Überlagerungen mit fehlerhaften Scans oder mit fehlerhaften Kassiereroperationen auf. Wir haben festgestellt, dass solche Duplikate sowohl innerhalb einer in Kafka verarbeiteten Charge als auch innerhalb von zwei parallel verarbeiteten Chargen auftreten können. Das Überprüfen auf Duplikate durch Abfragen der Datenbank ergab also nichts.Für jeden der Mikrodienste haben wir das Problem basierend auf der Geschäftslogik dieses Dienstes separat gelöst. Für Belege haben wir beispielsweise einen Scheck innerhalb des Stapels und eine separate Verarbeitung für das Auftreten von Duplikaten beim Einfügen hinzugefügt.
Damit die Arbeit der Benutzer mit der Betriebsgeschichte nicht das Wichtigste beeinflusst - die Funktionsweise unserer Geschäftsprozesse - haben wir alle historischen Daten in einen separaten Dienst mit einer separaten Datenbank aufgeteilt, die auch Informationen über Kafka erhält. Daher arbeiten Benutzer mit einem isolierten Dienst, ohne die Dienste zu beeinträchtigen, die Daten zu aktuellen Vorgängen verarbeiten.
Aufgabe 4. Wiederaufbereitung von Warteschlangen und Überwachung:
In verteilten Systemen treten zwangsläufig Probleme und Fehler bei der Verfügbarkeit von Datenbanken, Warteschlangen und externen Datenquellen auf. Im Fall von Markus ist die Ursache solcher Fehler die Integration in externe Systeme. Es war notwendig, eine Lösung zu finden, die wiederholte Anforderungen für fehlerhafte Antworten mit einem bestimmten Zeitlimit zulässt, aber gleichzeitig die Verarbeitung erfolgreicher Anforderungen in der Hauptwarteschlange nicht beendet. Hierfür wurde das sogenannte „Topic Based Retry“ -Konzept gewählt. Für jedes Hauptthema werden ein oder mehrere Wiederholungsthemen erstellt, an die fehlerhafte Nachrichten gesendet werden, und gleichzeitig wird die Verzögerung bei der Verarbeitung von Nachrichten aus dem Hauptthema beseitigt. Interaktionsschema -
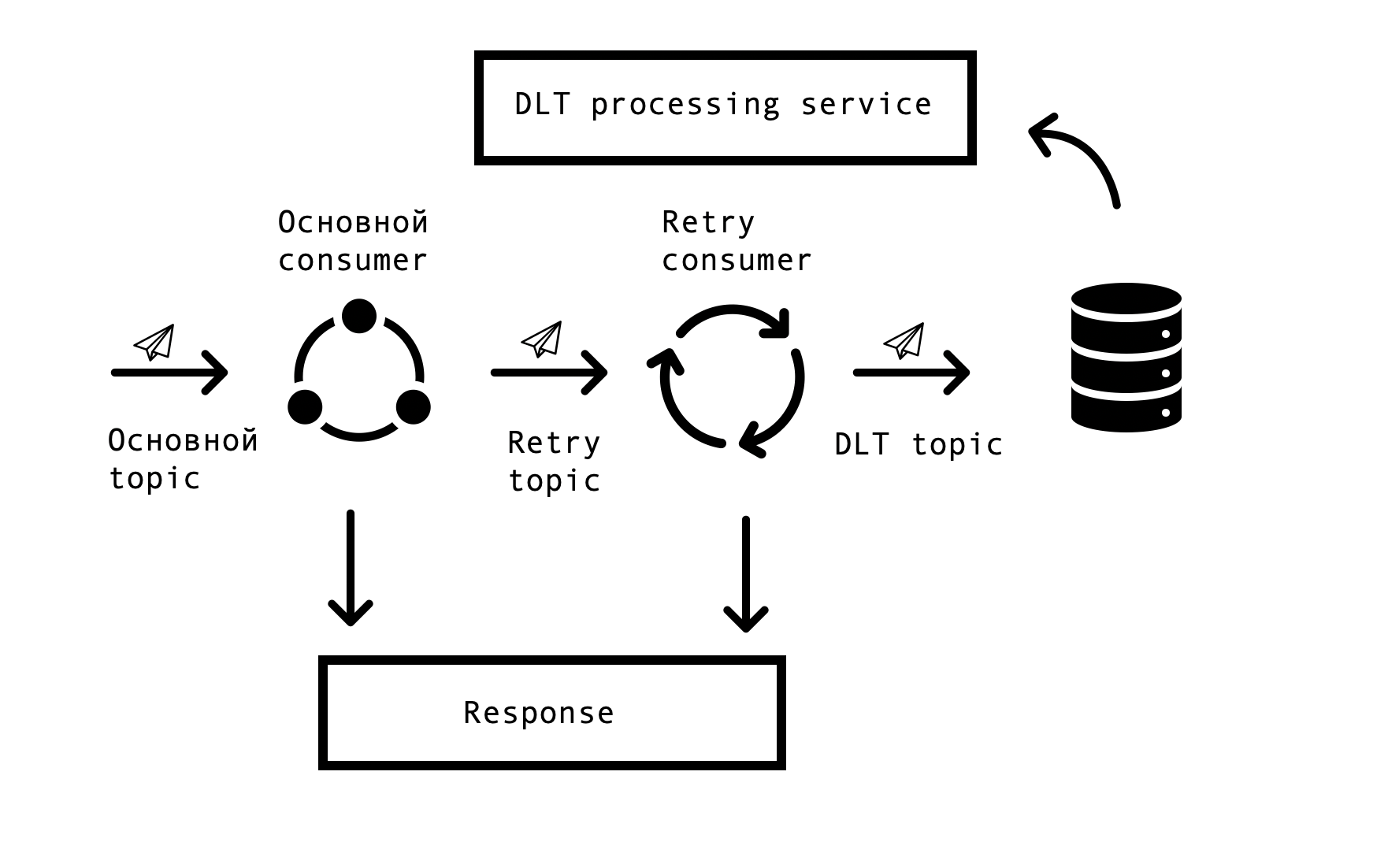
Um ein solches Schema zu implementieren, brauchten wir Folgendes: Um diese Lösung in Spring zu integrieren und Codeduplizierungen zu vermeiden. In der Weite des Netzwerks stießen wir auf eine ähnliche Lösung, die auf Spring BeanPostProccessor basiert, die uns jedoch unnötig umständlich erschien. Unser Team hat eine einfachere Lösung entwickelt, mit der wir uns in den Kundenerstellungszyklus von Spring integrieren und zusätzlich Retry Consumers hinzufügen können. Wir haben dem Spring-Team einen Prototyp unserer Lösung angeboten, den Sie hier sehen können . Die Anzahl der Wiederholungskonsumenten und die Anzahl der Versuche jedes Konsumenten wird über die Parameter konfiguriert, abhängig von den Anforderungen des Geschäftsprozesses. Damit alles funktioniert, muss nur noch die Annotation org.springframework.kafka.annotation.KafkaListener eingefügt werden, die allen Spring-Entwicklern bekannt ist.
Wenn die Nachricht nach allen Wiederholungsversuchen nicht verarbeitet werden konnte, wird sie mit Spring DeadLetterPublishingRecoverer an das DLT (Dead Letter Topic) gesendet. Auf Anfrage des Supports haben wir diese Funktionalität erweitert und einen separaten Dienst eingerichtet, mit dem Sie Nachrichten, stackTrace, traceId und andere nützliche Informationen zu diesen anzeigen können, die in DLT eingegangen sind. Darüber hinaus wurden allen DLT-Themen Überwachung und Warnungen hinzugefügt, und jetzt ist das Erscheinen einer Nachricht in einem DLT-Thema ein Grund für das Parsen und Feststellen eines Fehlers. Dies ist sehr praktisch - unter dem Namen des Themas verstehen wir sofort, in welchem Schritt des Prozesses das Problem aufgetreten ist, was die Suche nach seiner Grundursache erheblich beschleunigt.

In jüngerer Zeit haben wir eine Schnittstelle implementiert, über die wir Nachrichten von unserem Support erneut senden können, nachdem deren Ursachen beseitigt wurden (z. B. Wiederherstellung der Funktionsfähigkeit des externen Systems) und natürlich der entsprechende Fehler für die Analyse ermittelt wurde. Hier haben sich unsere Selbstthemen als nützlich erwiesen. Um eine lange Verarbeitungskette nicht neu zu starten, können Sie sie ab dem gewünschten Schritt neu starten.
Plattformbetrieb
Die Plattform ist bereits produktiv in Betrieb. Jeden Tag führen wir Lieferungen und Lieferungen durch, verbinden neue Vertriebszentren und Filialen. Im Rahmen des Pilotprojekts arbeitet das System mit den Warengruppen „Tabak“ und „Schuhe“.
Unser gesamtes Team ist an der Durchführung von Piloten, der Analyse neu auftretender Probleme und der Einreichung von Vorschlägen zur Verbesserung unseres Produkts beteiligt, von der Verbesserung der Protokolle bis hin zur Änderung von Prozessen.
Um unsere Fehler nicht zu wiederholen, werden alle während des Piloten gefundenen Fälle in automatisierten Tests widergespiegelt. Das Vorhandensein einer großen Anzahl von Autotests und Komponententests ermöglicht es Ihnen, Regressionstests durchzuführen und in nur wenigen Stunden einen Hotfix zu erstellen.
Jetzt entwickeln und verbessern wir unsere Plattform weiter und stehen ständig vor neuen Herausforderungen. Wenn Sie interessiert sind, werden wir Sie in den folgenden Artikeln über unsere Lösungen informieren.