
Es ist also an der Zeit, den zweiten Teil zu veröffentlichen. Heute werden wir unseren Code-Editor weiterentwickeln und ihm die automatische Vervollständigung und Fehlerhervorhebung hinzufügen. Außerdem werden wir darüber sprechen, warum ein Code-Editor
EditTextnicht zurückbleibt.
Bevor Sie weiterlesen, empfehle ich Ihnen dringend, den ersten Teil zu lesen .
Einführung
 Erinnern wir uns zunächst daran, wo wir im letzten Teil aufgehört haben . Wir haben eine optimierte Syntaxhervorhebung geschrieben, die den Text im Hintergrund analysiert und nur seinen sichtbaren Teil einfärbt sowie eine Zeilennummerierung hinzufügt (allerdings ohne Android-Zeilenumbrüche, aber immer noch).
Erinnern wir uns zunächst daran, wo wir im letzten Teil aufgehört haben . Wir haben eine optimierte Syntaxhervorhebung geschrieben, die den Text im Hintergrund analysiert und nur seinen sichtbaren Teil einfärbt sowie eine Zeilennummerierung hinzufügt (allerdings ohne Android-Zeilenumbrüche, aber immer noch).
In diesem Teil werden wir die Code-Vervollständigung und die Fehlerhervorhebung hinzufügen.
Code-Vervollständigung
Stellen wir uns zunächst vor, wie es funktionieren soll:
- Benutzer schreibt ein Wort
- Nach Eingabe der ersten N Zeichen wird ein Fenster mit Tipps angezeigt
- Wenn Sie auf den Hinweis klicken, wird das Wort automatisch "gedruckt".
- Das Fenster mit den Hinweisen wird geschlossen und der Cursor an das Ende des Wortes bewegt
- Wenn der Benutzer das im Tooltip angezeigte Wort selbst eingegeben hat, sollte das Fenster mit den Hinweisen automatisch geschlossen werden
Sieht es nicht nach irgendetwas aus? Android hat bereits eine Komponente mit genau der gleichen Logik - wir müssen also keine
MultiAutoCompleteTextViewKrücken mit PopupWindowuns schreiben (sie wurden bereits für uns geschrieben).
Der erste Schritt besteht darin, das Elternteil unserer Klasse zu ändern:
class TextProcessor @JvmOverloads constructor(
context: Context,
attrs: AttributeSet? = null,
defStyleAttr: Int = R.attr.autoCompleteTextViewStyle
) : MultiAutoCompleteTextView(context, attrs, defStyleAttr)
Jetzt müssen wir schreiben,
ArrayAdapterwelche die gefundenen Ergebnisse anzeigen. Der vollständige Adaptercode ist nicht verfügbar. Beispiele für die Implementierung finden Sie im Internet. Aber ich werde im Moment mit dem Filtern aufhören.
Um
ArrayAdapterzu verstehen, welche Hinweise angezeigt werden müssen, müssen wir die Methode überschreiben getFilter:
override fun getFilter(): Filter {
return object : Filter() {
private val suggestions = mutableListOf<String>()
override fun performFiltering(constraint: CharSequence?): FilterResults {
// ...
}
override fun publishResults(constraint: CharSequence?, results: FilterResults) {
clear() //
addAll(suggestions)
notifyDataSetChanged()
}
}
}
performFilteringFüllen Sie
in der Methode die Liste suggestionsder Wörter basierend auf dem Wort, das der Benutzer eingegeben hat (in einer Variablen enthalten constraint).
Woher erhalten Sie die Daten vor dem Filtern?
Es hängt alles von Ihnen ab - Sie können eine Art Interpreter verwenden, um nur gültige Optionen auszuwählen, oder den gesamten Text scannen, wenn Sie die Datei öffnen. Zur Vereinfachung des Beispiels werde ich eine vorgefertigte Liste von Optionen für die automatische Vervollständigung verwenden:
private val staticSuggestions = mutableListOf(
"function",
"return",
"var",
"const",
"let",
"null"
...
)
...
override fun performFiltering(constraint: CharSequence?): FilterResults {
val filterResults = FilterResults()
val input = constraint.toString()
suggestions.clear() //
for (suggestion in staticSuggestions) {
if (suggestion.startsWith(input, ignoreCase = true) &&
!suggestion.equals(input, ignoreCase = true)) {
suggestions.add(suggestion)
}
}
filterResults.values = suggestions
filterResults.count = suggestions.size
return filterResults
}
Die Filterlogik hier ist ziemlich primitiv. Wir gehen die gesamte Liste durch und vergleichen, ohne den Fall zu beachten, den Anfang der Zeichenfolge.
Installieren Sie den Adapter, schreiben Sie den Text - es funktioniert nicht. Was ist los? Beim ersten Link in Google stoßen wir auf eine Antwort, die besagt, dass wir die Installation vergessen haben
Tokenizer.
Wofür ist Tokenizer?
In einfachen Worten
Tokenizerhilft es zu MultiAutoCompleteTextViewverstehen, nach welchem eingegebenen Zeichen die Worteingabe als vollständig betrachtet werden kann. Es hat auch eine vorgefertigte Implementierung in Form der CommaTokenizerTrennung von Wörtern in Kommas, was in diesem Fall nicht zu uns passt.
Nun, da
CommaTokenizerwir nicht zufrieden sind, werden wir unsere eigenen schreiben:
Benutzerdefinierter Tokenizer
class SymbolsTokenizer : MultiAutoCompleteTextView.Tokenizer {
companion object {
private const val TOKEN = "!@#$%^&*()_+-={}|[]:;'<>/<.? \r\n\t"
}
override fun findTokenStart(text: CharSequence, cursor: Int): Int {
var i = cursor
while (i > 0 && !TOKEN.contains(text[i - 1])) {
i--
}
while (i < cursor && text[i] == ' ') {
i++
}
return i
}
override fun findTokenEnd(text: CharSequence, cursor: Int): Int {
var i = cursor
while (i < text.length) {
if (TOKEN.contains(text[i - 1])) {
return i
} else {
i++
}
}
return text.length
}
override fun terminateToken(text: CharSequence): CharSequence = text
}
Lassen Sie es uns herausfinden:
TOKEN - eine Zeichenfolge mit Zeichen, die ein Wort von einem anderen trennen. In den Methoden findTokenStartund findTokenEndgehen wir den Text auf der Suche nach diesen sehr trennenden Symbolen durch. Mit dieser Methode terminateTokenkönnen Sie ein geändertes Ergebnis zurückgeben, das wir jedoch nicht benötigen. Daher geben wir den Text einfach unverändert zurück.
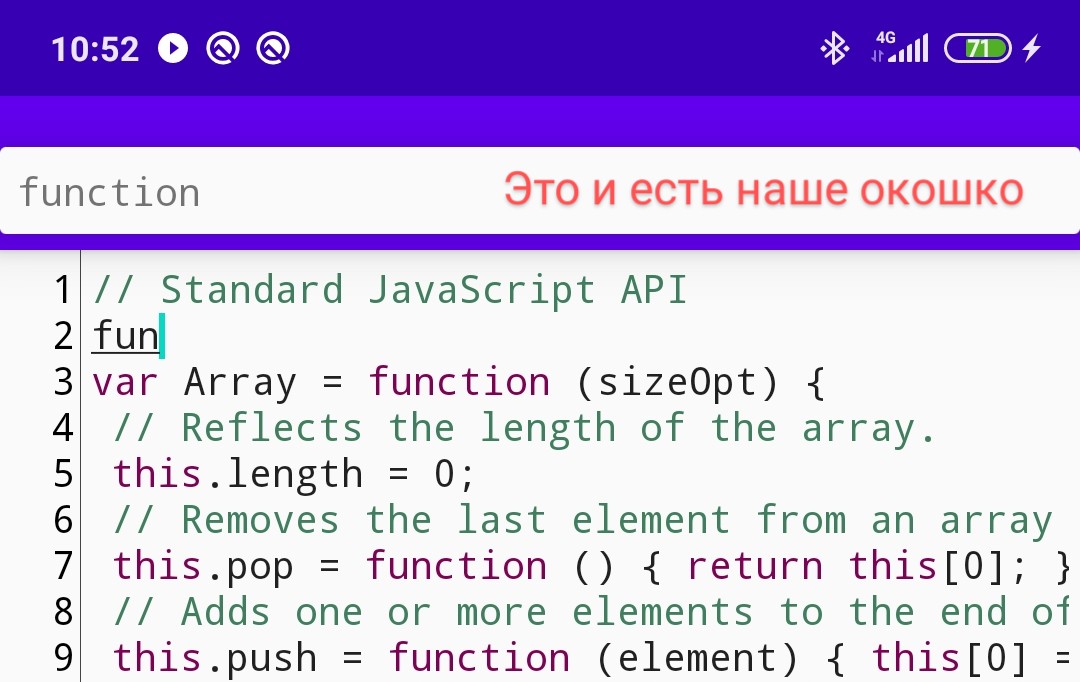
Ich bevorzuge es auch, eine Eingabeverzögerung von 2 Zeichen hinzuzufügen, bevor die Liste angezeigt wird:
textProcessor.threshold = 2Installieren, ausführen, Text schreiben - es funktioniert! Aber aus irgendeinem Grund verhält sich das Fenster mit den Spitzen seltsam - es wird in voller Breite angezeigt, seine Höhe ist klein und theoretisch sollte es unter dem Cursor erscheinen. Wie werden wir es reparieren?
Korrektur von Sehfehlern
Hier beginnt der Spaß, denn mit der API können wir nicht nur die Größe des Fensters, sondern auch seine Position ändern.
Lassen Sie uns zunächst die Größe festlegen. Meiner Meinung nach wäre die bequemste Option ein Fenster, das halb so hoch und breit wie der Bildschirm ist. Da sich jedoch unsere Größe
Viewje nach Tastaturstatus ändert, wählen wir die Größen in der Methode aus onSizeChanged:
override fun onSizeChanged(w: Int, h: Int, oldw: Int, oldh: Int) {
super.onSizeChanged(w, h, oldw, oldh)
updateSyntaxHighlighting()
dropDownWidth = w * 1 / 2
dropDownHeight = h * 1 / 2
}
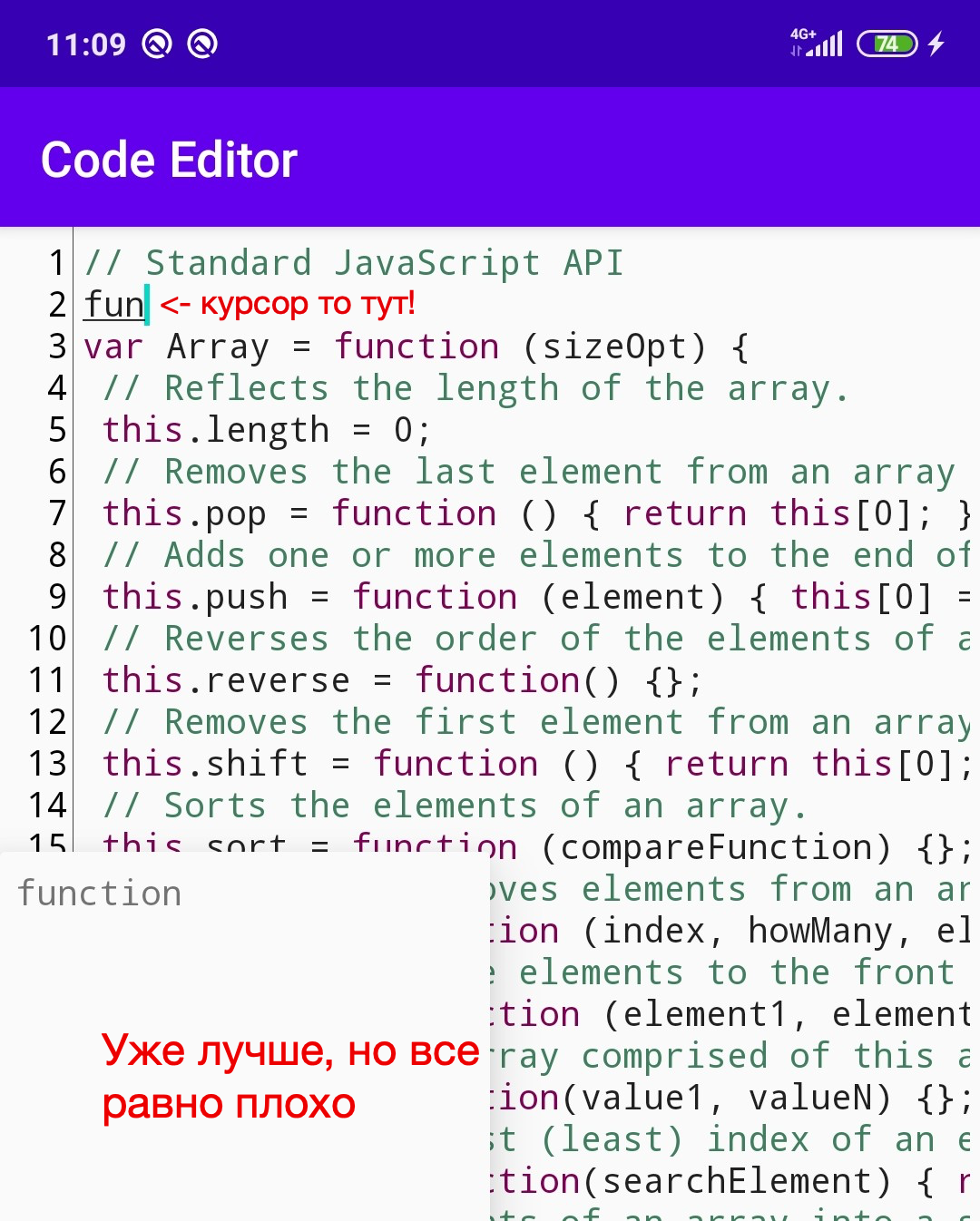 Es sieht besser aus, aber nicht viel. Wir möchten erreichen, dass das Fenster unter dem Cursor erscheint und sich während der Bearbeitung mitbewegt.
Es sieht besser aus, aber nicht viel. Wir möchten erreichen, dass das Fenster unter dem Cursor erscheint und sich während der Bearbeitung mitbewegt.
Wenn beim Bewegen entlang X alles ganz einfach ist - wir nehmen die Koordinate des Buchstabenanfangs und setzen diesen Wert auf
dropDownHorizontalOffset, dann wird die Auswahl der Höhe schwieriger.
Google über die Eigenschaften von Schriftarten können Sie auf diesen Beitrag stoßen . Das vom Autor angehängte Bild zeigt deutlich, mit welchen Eigenschaften wir die vertikale Koordinate berechnen können.

Schreiben wir nun eine Methode, die wir aufrufen, wenn sich der Text ändert in
onTextChanged:
private fun onPopupChangePosition() {
val line = layout.getLineForOffset(selectionStart) //
val x = layout.getPrimaryHorizontal(selectionStart) //
val y = layout.getLineBaseline(line) // baseline
val offsetHorizontal = x + gutterWidth //
dropDownHorizontalOffset = offsetHorizontal.toInt()
val offsetVertical = y - scrollY // -scrollY ""
dropDownVerticalOffset = offsetVertical
}
Anscheinend haben sie nichts vergessen - der X- Versatz funktioniert, aber der Y- Versatz wird falsch berechnet. Dies liegt daran, dass wir
dropDownAnchorim Markup nicht angegeben haben :
android:dropDownAnchor="@id/toolbar"Durch Angabe
Toolbarder Qualität dropDownAnchorteilen wir dem Widget mit, dass die Dropdown-Liste darunter angezeigt wird .
Wenn wir jetzt mit der Bearbeitung des Textes beginnen, wird alles funktionieren, aber im Laufe der Zeit werden wir feststellen, dass das Fenster, wenn es nicht unter den Cursor passt, mit einem großen Einzug nach oben gezogen wird, der hässlich aussieht. Es ist Zeit, eine Krücke zu schreiben:

val offset = offsetVertical + dropDownHeight
if (offset < getVisibleHeight()) {
dropDownVerticalOffset = offsetVertical
} else {
dropDownVerticalOffset = offsetVertical - dropDownHeight
}
...
private fun getVisibleHeight(): Int {
val rect = Rect()
getWindowVisibleDisplayFrame(rect)
return rect.bottom - rect.top
}
Wir müssen den Einzug nicht ändern, wenn die Summe
offsetVertical + dropDownHeightkleiner als die sichtbare Höhe des Bildschirms ist, da in diesem Fall das Fenster unter dem Cursor platziert wird. Aber wenn es noch mehr ist, subtrahieren wir vom Einzug dropDownHeight- so passt er über den Cursor ohne einen großen Einzug, den das Widget selbst hinzufügt.
PS Sie können sehen, wie die Tastatur auf dem GIF blinkt, und um ehrlich zu sein, ich weiß nicht, wie ich das beheben soll. Wenn Sie also eine Lösung haben, schreiben Sie.
Fehler hervorheben
Mit der Hervorhebung von Fehlern ist alles viel einfacher als es scheint, da wir selbst Syntaxfehler im Code nicht direkt erkennen können - wir werden eine Parser-Bibliothek eines Drittanbieters verwenden. Da ich einen Editor für JavaScript schreibe, fiel meine Wahl auf Rhino , eine beliebte JavaScript-Engine, die sich bewährt hat und immer noch unterstützt wird.
Wie werden wir analysieren?
Das Starten von Rhino ist eine ziemlich umständliche Operation, daher ist das Ausführen des Parsers nach jedem eingegebenen Zeichen (wie wir es beim Hervorheben getan haben) überhaupt keine Option. Um dieses Problem zu lösen, verwende ich die RxBinding- Bibliothek . Für diejenigen, die RxJava nicht in das Projekt ziehen möchten, können Sie ähnliche Optionen ausprobieren .
Der Betreiber
debouncehilft uns dabei, das zu erreichen, was wir wollen, und wenn Sie mit ihm nicht vertraut sind, empfehle ich Ihnen, diesen Artikel zu lesen .
textProcessor.textChangeEvents()
.skipInitialValue()
.debounce(1500, TimeUnit.MILLISECONDS)
.filter { it.text.isNotEmpty() }
.distinctUntilChanged()
.observeOn(AndroidSchedulers.mainThread())
.subscribeBy {
//
}
.disposeOnFragmentDestroyView()
Schreiben wir nun ein Modell, das der Parser an uns zurückgibt:
data class ParseResult(val exception: RhinoException?)Ich schlage vor, die folgende Logik zu verwenden: Wenn keine Fehler gefunden werden,
exceptionwird es solche geben null. Andernfalls erhalten wir ein Objekt RhinoException, das alle erforderlichen Informationen enthält - Zeilennummer, Fehlermeldung, StackTrace usw.
Nun, eigentlich das Parsen selbst:
// !
val context = Context.enter() // org.mozilla.javascript.Context
context.optimizationLevel = -1
context.maximumInterpreterStackDepth = 1
try {
val scope = context.initStandardObjects()
context.evaluateString(scope, sourceCode, fileName, 1, null)
return ParseResult(null)
} catch (e: RhinoException) {
return ParseResult(e)
} finally {
Context.exit()
}
Verständnis:
Das Wichtigste hier ist die Methode
evaluateString- sie ermöglicht es Ihnen, den Code, den wir als Zeichenfolge übergeben haben, auszuführen sourceCode. Der fileNameDateiname wird in angezeigt - er wird fehlerhaft angezeigt, Einheit ist die Zeilennummer, mit der gezählt werden soll, das letzte Argument ist die Sicherheitsdomäne, aber wir brauchen sie nicht, also setzen wir null.
Optimierungslevel und MaximumInterpreterStackDepth
Mit einem Parameter
optimizationLevelmit einem Wert von 1 bis 9 können Sie bestimmte Code-Optimierungen (Datenflussanalyse, Typflussanalyse usw.) aktivieren, wodurch eine einfache Syntaxfehlerprüfung zu einer sehr zeitaufwändigen Operation wird, die wir nicht benötigen.
Wenn Sie es mit dem Wert 0 verwenden , werden alle diese "Optimierungen" nicht angewendet. Wenn ich es jedoch richtig verstehe, verwendet Rhino weiterhin einige der Ressourcen, die für die einfache Fehlerprüfung nicht benötigt werden, was bedeutet, dass es nicht zu uns passt.
Es bleibt nur ein negativer Wert - durch Angabe von -1 aktivieren wir den "Interpreter" -Modus, genau das, was wir brauchen. Die Dokumentation besagt, dass dies der schnellste und wirtschaftlichste Weg ist, Rhino auszuführen.
Mit dem Parameter
maximumInterpreterStackDepthkönnen Sie die Anzahl der rekursiven Aufrufe begrenzen.
Stellen wir uns vor, was passiert, wenn Sie diesen Parameter nicht angeben:
- Der Benutzer schreibt den folgenden Code:
function recurse() { recurse(); } recurse(); - Rhino führt den Code aus und in einer Sekunde stürzt unsere Anwendung ab
OutOfMemoryError. Das Ende.
Fehler anzeigen
Wie ich bereits sagte, haben wir, sobald wir den
ParseResultenthaltenen erhalten RhinoException, alle erforderlichen Datensätze zur Anzeige, einschließlich der Zeilennummer - wir müssen nur die Methode aufrufen lineNumber().
Lassen Sie uns jetzt die rote Wellenlinie Spanne schreiben , dass ich kopiert Stackoverflow . Es gibt viel Code, aber die Logik ist einfach: Zeichnen Sie zwei kurze rote Linien in verschiedenen Winkeln.
ErrorSpan.kt
class ErrorSpan(
private val lineWidth: Float = 1 * Resources.getSystem().displayMetrics.density + 0.5f,
private val waveSize: Float = 3 * Resources.getSystem().displayMetrics.density + 0.5f,
private val color: Int = Color.RED
) : LineBackgroundSpan {
override fun drawBackground(
canvas: Canvas,
paint: Paint,
left: Int,
right: Int,
top: Int,
baseline: Int,
bottom: Int,
text: CharSequence,
start: Int,
end: Int,
lineNumber: Int
) {
val width = paint.measureText(text, start, end)
val linePaint = Paint(paint)
linePaint.color = color
linePaint.strokeWidth = lineWidth
val doubleWaveSize = waveSize * 2
var i = left.toFloat()
while (i < left + width) {
canvas.drawLine(i, bottom.toFloat(), i + waveSize, bottom - waveSize, linePaint)
canvas.drawLine(i + waveSize, bottom - waveSize, i + doubleWaveSize, bottom.toFloat(), linePaint)
i += doubleWaveSize
}
}
}
Jetzt können Sie eine Methode zum Installieren von span in die Problemzeile schreiben:
fun setErrorLine(lineNumber: Int) {
if (lineNumber in 0 until lineCount) {
val lineStart = layout.getLineStart(lineNumber)
val lineEnd = layout.getLineEnd(lineNumber)
text.setSpan(ErrorSpan(), lineStart, lineEnd, Spannable.SPAN_EXCLUSIVE_EXCLUSIVE)
}
}
Es ist wichtig, sich daran zu erinnern, dass der Benutzer möglicherweise Zeit hat, einige Codezeilen zu löschen, da das Ergebnis mit einer Verzögerung einhergeht. Dies
lineNumberkann sich dann als ungültig herausstellen.
 Um es nicht zu bekommen,
Um es nicht zu bekommen, IndexOutOfBoundsExceptionfügen wir gleich zu Beginn einen Scheck hinzu. Nun, dann berechnen wir nach dem bekannten Schema das erste und letzte Zeichen der Zeichenkette, wonach wir die Spanne einstellen.
Die Hauptsache ist nicht zu vergessen, den Text aus den bereits festgelegten Bereichen zu löschen
afterTextChanged:
fun clearErrorSpans() {
val spans = text.getSpans<ErrorSpan>(0, text.length)
for (span in spans) {
text.removeSpan(span)
}
}
Warum bleiben Code-Editoren zurück?
In zwei Artikeln haben wir einen guten Code-Editor geschrieben, der von
EditTextund erbt MultiAutoCompleteTextView, aber wir können uns nicht der Leistung rühmen, wenn wir mit großen Dateien arbeiten.
Wenn Sie dieselbe TextView.java für mehr als 9k Codezeilen öffnen , wird jeder Texteditor, der nach dem gleichen Prinzip wie wir geschrieben wurde, verzögert.
F: Warum bleibt QuickEdit dann nicht zurück?
A: Weil es unter der Haube weder
EditTextnoch verwendet TextView.
In letzter Zeit werden Code-Editoren in CustomView immer beliebter ( hier und da , na ja , oder hier und da, Da sind viele von denen). In der Vergangenheit verfügt TextView über zu viel redundante Logik, die Code-Editoren nicht benötigen. Die ersten Dinge, die mir in den Sinn kommen, sind Autofill , Emoji , Compound Drawables , anklickbare Links usw.
Wenn ich es richtig verstanden habe, haben die Autoren der Bibliotheken all dies einfach losgeworden, wodurch sie einen Texteditor erhalten haben, der mit Dateien von einer Million Zeilen arbeiten kann, ohne den UI-Thread stark zu belasten. (Obwohl ich mich teilweise irre, habe ich die Quelle nicht viel verstanden.)
Es gibt eine andere Option, die meiner Meinung nach weniger attraktiv ist - Code-Editoren in WebView ( hier und da)es gibt auch viele davon). Ich mag sie nicht, weil die Benutzeroberfläche in WebView schlechter aussieht als die native, und sie verlieren auch in Bezug auf die Leistung gegenüber den Editoren in CustomView.
Fazit
Wenn Sie einen Code-Editor schreiben und die Spitze von Google Play erreichen möchten, verschwenden Sie keine Zeit und erstellen Sie eine vorgefertigte Bibliothek in CustomView. Wenn Sie eine einzigartige Erfahrung machen möchten, schreiben Sie alles selbst mit nativen Widgets.
Ich werde auch einen Link zum Quellcode meines Code-Editors auf GitHub hinterlassen. Dort finden Sie nicht nur die Funktionen, über die ich Ihnen in diesen beiden Artikeln berichtet habe, sondern auch viele andere, die nicht beachtet wurden.
Vielen Dank!