
Natürlich ist NSPK kein Startup, aber in den ersten Jahren seines Bestehens herrschte im Unternehmen eine solche Atmosphäre, und das waren sehr interessante Jahre. Mein Name ist Dmitry Kornyakov . Ich unterstütze seit über 10 Jahren Linux-Infrastrukturen mit hohen Verfügbarkeitsanforderungen. Er trat im Januar 2016 dem NSPK-Team bei und sah leider nicht den Beginn des Bestehens des Unternehmens, sondern befand sich im Stadium großer Veränderungen.
Generell können wir sagen, dass unser Team 2 Produkte für das Unternehmen liefert. Der erste ist die Infrastruktur. Mail sollte gehen, DNS sollte funktionieren und Domänencontroller sollten Sie auf Servern lassen, die nicht fallen sollten. Die IT-Landschaft des Unternehmens ist riesig! Dies sind geschäfts- und unternehmenskritische Systeme. Die Verfügbarkeitsanforderungen für einige sind 99.999. Das zweite Produkt sind die physischen und virtuellen Server selbst. Die bestehenden müssen überwacht werden, und neue werden regelmäßig an Kunden aus vielen Abteilungen geliefert. In diesem Artikel möchte ich mich darauf konzentrieren, wie wir die Infrastruktur entwickelt haben, die für den Lebenszyklus von Servern verantwortlich ist.
Der Anfang des Pfades
Am Anfang des Pfades sah unser Technologie-Stack folgendermaßen aus:
OS CentOS 7-
Domänencontroller FreeIPA
Automation - Ansible (+ Tower), Cobbler
All dies befand sich in drei Domänen, die auf mehrere Rechenzentren verteilt waren. In einem Rechenzentrum - Bürosysteme und Teststandorte, im Rest PROD.
Irgendwann sah die Erstellung von Servern folgendermaßen aus:
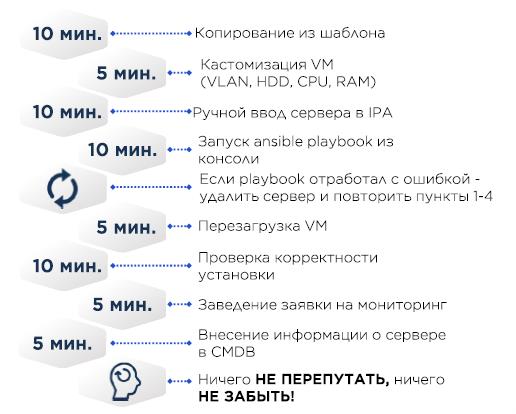
In der VM CentOS-Minimalvorlage und der erforderlichen Minimalvorlage, wie in der korrekten Datei /etc/resolv.conf, erfolgt der Rest über Ansible.
CMDB - Excel.
Wenn der Server physisch ist, wurde anstelle des Kopierens der virtuellen Maschine das Betriebssystem mit Cobbler darauf installiert. Die MAC-Adressen des Zielservers werden der Cobbler-Konfiguration hinzugefügt, der Server erhält eine IP-Adresse über DHCP und das Betriebssystem wird gegossen.
Zuerst haben wir sogar versucht, eine Art Konfigurationsmanagement in Cobbler durchzuführen. Im Laufe der Zeit kam es jedoch zu Problemen mit der Portabilität von Konfigurationen sowohl für andere Rechenzentren als auch für Ansible-Code zur Vorbereitung der VM.
Zu dieser Zeit empfanden viele von uns Ansible als eine bequeme Erweiterung von Bash und sparten nicht an Konstruktionen mit der Shell, sed. Im Allgemeinen Bashsible. Dies führte letztendlich dazu, dass es einfacher war, den Server zu löschen, das Playbook zu reparieren und erneut auszuführen, wenn das Playbook aus irgendeinem Grund auf dem Server nicht funktionierte. Tatsächlich gab es keine Skriptversionierung und auch keine Portabilität der Konfiguration.
Zum Beispiel wollten wir einige Konfigurationen auf allen Servern ändern:
- Wir ändern die Konfiguration auf vorhandenen Servern im logischen Segment / Rechenzentrum. Manchmal nicht über Nacht - Verfügbarkeitsanforderungen und das Gesetz der großen Anzahl erlauben es nicht, alle Änderungen auf einmal anzuwenden. Einige Änderungen sind potenziell destruktiv und erfordern einen Neustart - von den Diensten bis zum Betriebssystem.
- Fixierung in Ansible
- Fixierung in Cobbler
- N-mal für jedes logische Segment / Rechenzentrum wiederholen
Damit alle Änderungen reibungslos ablaufen konnten, mussten viele Faktoren berücksichtigt werden, und es treten ständig Änderungen auf.
- Refactoring von ansible Code, Konfigurationsdateien
- Interne Best Practice ändern
- Änderungen nach der Analyse von Vorfällen / Unfällen
- Interne und externe Sicherheitsstandards ändern. Beispielsweise wird PCI DSS jedes Jahr mit neuen Anforderungen aktualisiert
Infrastrukturwachstum und Beginn des Pfades Die
Anzahl der Server / logischen Domänen / Rechenzentren und damit die Anzahl der Fehler in Konfigurationen. Irgendwann kamen wir zu drei Richtungen, in die wir das Konfigurationsmanagement entwickeln müssen:
- Automatisierung. Der menschliche Faktor bei sich wiederholenden Operationen sollte so weit wie möglich vermieden werden.
- . , . . – , .
- configuration management.
Es bleiben noch ein paar Werkzeuge hinzuzufügen.
Wir haben GitLab CE als Code-Repository ausgewählt, nicht zuletzt für die integrierten CI / CD-Module.
Gewölbe der Geheimnisse - Hashicorp-Gewölbe, inkl. für die tolle API.
Testkonfigurationen und Ansible-Rollen - Molecule + Testinfra. Tests laufen viel schneller, wenn sie mit ansible Mitogen verbunden sind. Parallel dazu haben wir begonnen, eine eigene CMDB und einen Orchestrator für die automatische Bereitstellung zu schreiben (im Bild über Cobbler). Dies ist jedoch eine ganz andere Geschichte, die mein Kollege und der Hauptentwickler dieser Systeme in Zukunft erzählen werden.
Unsere Wahl:
Molekül + Testinfra
Ansible + Tower + AWX Server
World + DITNET (Inhouse)
Cobbler
Gitlab + GitLab-Läufer
Hashicorp Vault

Apropos ansible Rollen. Anfangs war es alleine, nach mehreren Refactorings gibt es 17 davon. Ich empfehle dringend, den Monolithen in idempotente Rollen zu unterteilen, die dann separat ausgeführt werden können. Sie können zusätzlich Tags hinzufügen. Wir haben die Rollen nach Funktionen unterteilt - Netzwerk, Protokollierung, Pakete, Hardware, Molekül usw. Im Allgemeinen haben wir uns an die folgende Strategie gehalten. Ich bestehe nicht darauf, dass dies die einzige Wahrheit ist, aber es hat bei uns funktioniert.
- Das Kopieren von Servern vom "goldenen Bild" ist böse!
Der Hauptnachteil besteht darin, dass Sie nicht genau wissen, in welchem Status sich die Images gerade befinden, und dass alle Änderungen an allen Images in allen Virtualisierungsfarmen vorgenommen werden. - Verwenden Sie die Standardkonfigurationsdateien auf ein Minimum und stimmen Sie mit anderen Abteilungen ab, für welche Kernsystemdateien Sie verantwortlich sind , zum Beispiel:
- /etc/sysctl.conf , /etc/sysctl.d/. , .
- override systemd .
- , sed
- :
- ! Ansible-lint, yaml-lint, etc
- ! bashsible.
- Ansible molecule .
- , ( 100) 70000 . .

Unsere Implementierung
Die ansiblen Rollen wurden also von Lintern vorbereitet, erstellt und überprüft. Und sogar Gits werden überall aufgezogen. Die Frage der zuverlässigen Lieferung von Code an verschiedene Segmente blieb jedoch offen. Wir haben uns entschieden, mit Skripten zu synchronisieren. Es sieht so aus:

Nachdem die Änderung eingetroffen ist, wird CI gestartet, ein Testserver erstellt, Rollen werden gerollt und mit einem Molekül getestet. Wenn alles in Ordnung ist, geht der Code an die Produktionsabteilung. Wir wenden den neuen Code jedoch nicht auf die vorhandenen Server im Computer an. Dies ist eine Art Stopper, der für die hohe Verfügbarkeit unserer Systeme notwendig ist. Und wenn die Infrastruktur riesig wird, kommt das Gesetz der großen Anzahl ins Spiel - selbst wenn Sie sicher sind, dass die Änderung harmlos ist, kann dies zu traurigen Konsequenzen führen.
Es gibt auch viele Optionen zum Erstellen von Servern. Am Ende haben wir uns für benutzerdefinierte Python-Skripte entschieden. Und für CI ansible:
- name: create1.yml - Create a VM from a template
vmware_guest:
hostname: "{{datacenter}}".domain.ru
username: "{{ username_vc }}"
password: "{{ password_vc }}"
validate_certs: no
cluster: "{{cluster}}"
datacenter: "{{datacenter}}"
name: "{{ name }}"
state: poweredon
folder: "/{{folder}}"
template: "{{template}}"
customization:
hostname: "{{ name }}"
domain: domain.ru
dns_servers:
- "{{ ipa1_dns }}"
- "{{ ipa2_dns }}"
networks:
- name: "{{ network }}"
type: static
ip: "{{ip}}"
netmask: "{{netmask}}"
gateway: "{{gateway}}"
wake_on_lan: True
start_connected: True
allow_guest_control: True
wait_for_ip_address: yes
disk:
- size_gb: 1
type: thin
datastore: "{{datastore}}"
- size_gb: 20
type: thin
datastore: "{{datastore}}"Dazu sind wir gekommen, das System lebt und entwickelt sich weiter.
- 17 ansible Rollen für die Konfiguration des Servers. Jede der Rollen dient zur Lösung einer separaten logischen Aufgabe (Protokollierung, Überwachung, Benutzerautorisierung, Überwachung usw.).
- Rollentests. Molekül + TestInfra.
- Eigene Entwicklung: CMDB + Orchestrator.
- Servererstellungszeit ~ 30 Minuten, automatisiert und praktisch unabhängig von der Aufgabenwarteschlange.
- Der gleiche Status / Name der Infrastruktur in allen Segmenten - Playbooks, Repositorys, Virtualisierungselemente.
- Tägliche Überprüfung des Serverstatus mit Erstellung von Berichten über Abweichungen vom Standard.
Ich hoffe, meine Geschichte wird für diejenigen nützlich sein, die am Anfang der Reise stehen. Welchen Automatisierungsstapel verwenden Sie?