In meinem Vortrag erinnerte ich mich an die Entwicklung von Python im Unternehmen: von den ersten Diensten, die in Deb-Paketen verpackt und auf Bare-Metal-Basis eingeführt wurden, bis zu einem komplexen Mono-Repository mit eigenem Build-System und eigener Cloud. Mehr in der Geschichte werden Django, Flask, Tornado, Docker, PyCharm, IPv6 und andere Dinge sein, denen wir im Laufe der Jahre begegnet sind.
- Lass mich dir von mir erzählen. Ich bin 2008 zu Yandex gekommen. Zuerst habe ich Content-Services durchgeführt, insbesondere Yandex.Afisha. Ich habe dort in Python geschrieben, wir haben den Service von Perl und anderen lustigen Technologien umgeschrieben.
Dann wechselte ich zu internen Diensten. Die Abteilung für interne Dienste wurde schrittweise in die Verwaltung von Suchschnittstellen und Diensten für Organisationen umgewandelt. Es ist viel Zeit vergangen, von einem einfachen Entwickler, den ich zum Leiter der Python-Entwicklung unserer Abteilung herangewachsen bin, ungefähr 30 Personen.
Ein wichtiger Punkt: Das Unternehmen ist sehr groß und ich kann nicht für alle Yandex sprechen. Ich kommuniziere natürlich mit Kollegen aus anderen Abteilungen, ich weiß, wie sie leben. Grundsätzlich kann ich aber nur über unsere Abteilung, über unsere Produkte sprechen. Mein Bericht wird sich darauf konzentrieren. Manchmal werde ich dir sagen, dass sie irgendwo anders in Yandex dies und das tun. Das kommt aber nicht oft vor.
Python wird an vielen Stellen im Unternehmen verwendet: in jeder Technologie, in jedem Technologie-Stack, in jeder Sprache. Alles, was irgendwo im Unternehmen in den Sinn kommt, ist entweder in Form eines Experiments oder in Form eines anderen. Und in jedem Yandex-Dienst wird es definitiv Python in der einen oder anderen Komponente geben.
Alles, was ich Ihnen sagen werde, ist meine Interpretation der Ereignisse. Ich gebe nicht vor, hundertprozentig objektiv zu sein. All dies ging auch durch meine Hände, es war emotional gefärbt. Alle meine Erfahrungen sind so persönlich.

Wie wird der Bericht aufgebaut sein? Um es Ihnen leichter zu machen, Informationen wahrzunehmen und zu erzählen, habe ich beschlossen, die gesamte Entwicklung von 2007 bis zum aktuellen Moment in mehrere Epochen zu unterteilen. Der Bericht wird streng nach diesen Epochen strukturiert. Die Ära bedeutet eine radikale Veränderung der Infrastruktur oder des Entwicklungsansatzes. Wenn sich unsere Eiseninfrastruktur ändert und wir gleichzeitig ändern, wie wir Dienstleistungen entwickeln und welche Tools wir verwenden, ist dies eine Ära. Es ist klar, dass ich mich ein wenig anpassen musste. Es ist klar, dass nicht alles synchron ablief und es Lücken zwischen diesen Änderungen gab, aber ich habe versucht, alles unter eine Zeitachse zu bringen, um es kompakter zu machen.
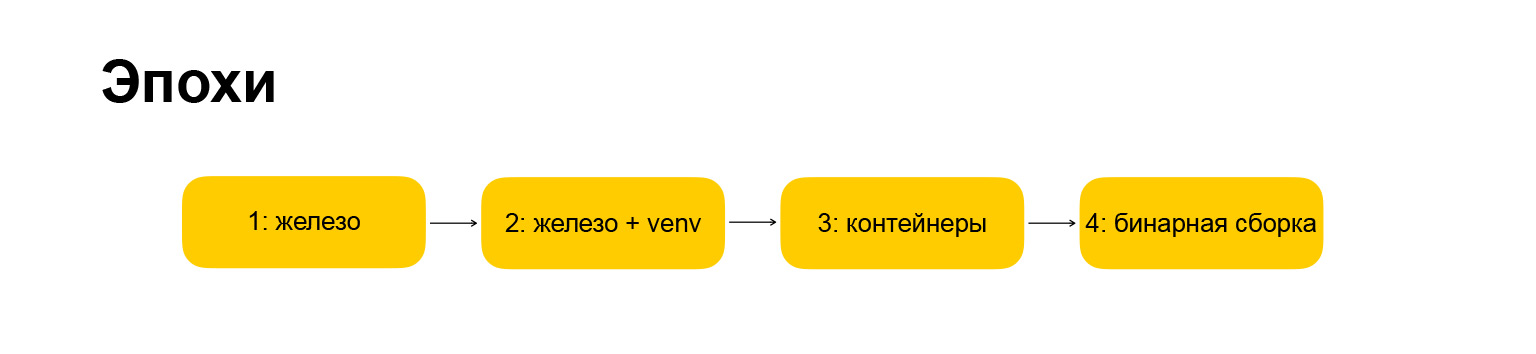
Welche Ära hatten wir? Auch hier ist alles urheberrechtlich geschützt, alle Namen gehören mir. Die erste Ära heißt "Eisen". Hier haben wir angefangen, als ich zur Firma kam. Daher hat sich alles ein wenig verändert. Die Ära ist zu "iron + venv" geworden. Weiter werde ich enthüllen, was sich hinter diesen Namen verbirgt. Zunächst möchte ich Ihnen einen Leitfaden geben, was ich Ihnen sagen werde.
Die nächste Ära ist "Container", hier ist alles mehr oder weniger klar. Die Ära, in die wir gerade eintreten, ist „binäre Assemblierung“, ich werde auch darüber erzählen.

Wie wird jede Ära strukturiert sein? Dies ist auch wichtig, weil ich eine rhythmische Erzählung machen wollte, damit jeder Abschnitt streng strukturiert und leichter zu verstehen war. Die Ära wird durch die Infrastruktur, die Frameworks, die wir verwenden, wie wir mit Abhängigkeiten arbeiten, welche Art von Entwicklungsumgebung wir haben und die Vor- und Nachteile dieses oder jenes Ansatzes beschrieben.
(Technische Pause.) Ich habe Ihnen die Einführung gesagt, ich habe Ihnen gesagt, wie der Bericht aufgebaut sein wird. Fahren wir mit der Geschichte selbst fort.
Alter 1: Eisen
Der erste Service, den ich begann, als ich in die Firma eintrat, hieß "Where Everybody Goes". Es war der Afisha-Satellit, der erste große Dienst auf Django.
Grisha BakunovBobukkann sagen, warum er sich einmal entschlossen hat, Django nach Yandex zu verlegen - im Allgemeinen ist es passiert. Wir haben angefangen, Dienstleistungen in Django zu erbringen.
Ich kam und sie sagten mir: Lass uns machen, wohin alle gehen. Dann gab es schon eine Art Basis. Ich habe mich verbunden und wir dachten, es wäre eine Art Experiment - wird es funktionieren oder nicht? Das Experiment erwies sich als erfolgreich. Alle waren sich einig, dass es möglich ist, Webdienste in Yandex in Python und Django zu erstellen. Fein! Unsere Infrastruktur ist dafür bereit, die Menschen sind bereit, die Welt ist auch bereit. Lassen Sie uns loslegen und Python und Django im gesamten Unternehmen weiter vertreiben. Wir haben damit angefangen. Wir haben Yandex.Afish, Weather umgeschrieben. Dann - das Fernsehprogramm. Dann ging alles wie ein Nebel, sie fingen an, alles neu zu schreiben.
Zu diesem Zeitpunkt sah die Yandex-Infrastruktur so aus, als wäre das gesamte Backend größtenteils in Pluszeichen geschrieben. Offensichtlich hat der Schritt in Richtung Python die Entwicklung vielerorts erheblich beschleunigt, und dies wurde von Unternehmen und Management gut aufgenommen. Lassen Sie uns nun über die Infrastruktur sprechen - wo haben diese Dienste funktioniert, worauf haben sie sich ausgewirkt und so weiter.

Dies waren Eisenautos, daher der Name dieser Ära. Was sind Eisenmaschinen? Sie sind nur Server im Rechenzentrum. Es gibt viele Server, die alle zu einem Cluster von beispielsweise 15 Computern zusammengefasst sind. Dann waren es 30, dann 50, 100. Und das alles auf Debian oder Ubuntu. Zu diesem Zeitpunkt waren wir von Debian nach Ubuntu migriert. Wir haben alle Anwendungen über einen Standard-Init-Prozess gestartet. Alles war Standard, wie damals. Für die Kommunikation unserer Anwendungen auf dem Webserver haben wir das FastCGI-Protokoll und die Flup-Bibliothek verwendet. Wenn Sie schon lange mit Python arbeiten, haben Sie wahrscheinlich schon davon gehört. Aber jetzt bin ich sicher, dass Sie es nicht verwenden, da es veraltet ist und eine sehr seltsame Sache war. Es hat sehr langsam funktioniert.
In diesem Moment gab es offensichtlich kein drittes Python, das wir in Python 2.3 geschrieben haben. Dann migrierten sie zu 2.4. Wilde Zeiten. Ich möchte nicht einmal an sie denken, weil die Sprache, die Gemeinschaften und das Ökosystem völlig anders aussahen, obwohl es auch cool war und viele davon damals angezogen wurden. Persönlich hat es mich in die Welt von Python eingetaucht - dass trotz der Besonderheiten und Kuriositäten bereits klar war, dass Python eine vielversprechende Technologie ist, können Sie Ihre Zeit dort investieren.
Ein wichtiger Punkt: Dann haben wir noch kein Nginx verwendet, keinen Apache mehr, sondern einen Webserver namens Lighttpd. Wenn Sie schon lange Webdienste erstellen, haben Sie wahrscheinlich auch davon gehört. Einmal war er sehr beliebt.

Von den Frameworks haben wir tatsächlich Django verwendet. Wir haben angefangen, große Dienstleistungen in Django zu erbringen. Irgendwo in der Firma gab es CherryPy, irgendwo - Web.py. Möglicherweise haben Sie auch von diesen Frameworks gehört. Jetzt sind sie nicht in den ersten Rollen, sie wurden lange von jüngeren und gewagten Rahmenbedingungen beiseite geschoben. Dann hatten sie ihre eigene Nische, aber irgendwann starben sie früher oder später aus, wir hörten auf, irgendetwas an ihnen zu tun. Sie fingen an, alles in Django zu machen.
Zu diesem Zeitpunkt war Python im Unternehmen so weit verbreitet, dass es über unsere Abteilung hinausging: Überall im Unternehmen wurden Webdienste in Python und Django erstellt.

Fahren wir mit der Arbeit mit Abhängigkeiten fort. Und hier ist so etwas, auf das Sie höchstwahrscheinlich auch gestoßen sind, wenn Sie für ein großes Unternehmen gearbeitet haben: Das Unternehmen verfügt bereits über eine etablierte Infrastruktur, an die Sie sich anpassen müssen. Yandex verfügte über eine Deb-Infrastruktur und interne Repositories für Deb-Pakete. Es wurde angenommen, dass der Yandex-Entwickler wusste, wie man dieses Deb-Paket kompiliert. Wir waren gezwungen, uns in diesen Ablauf zu integrieren, haben unsere Projekte in Form von vollwertigen Deb-Paketen zusammengestellt und dann als Deb-Paket all dies auf die Server gestellt, über die ich gesprochen habe, und dann wurden sie auch in Form von Deb-Paketen in Clustern angeordnet.
Infolgedessen mussten alle Abhängigkeiten und Bibliotheken, die gleichen Django, auch in Deb-Paketen gepackt werden. Zu diesem Zweck haben wir unsere eigene Infrastruktur erstellt, das interne Repository erweitert und gelernt, wie das geht. Dies ist keine sehr originelle Lektion: Wenn Sie versucht haben, ein RPM- oder Deb-Paket zu erstellen, wissen Sie Bescheid. RPM ist etwas einfacher, Deb ist komplizierter. Aber trotzdem - Sie können nicht einfach von der Straße kommen und mit einem Klick loslegen. Sie müssen ein wenig graben.
Danach bauen wir seit vielen Jahren Deb-Pakete. Und es scheint mir, dass nicht jeder, der dies für die Arbeit getan hat, verstanden hat, was unter der Haube geschah. Sie nahmen nur voneinander, kopierten Leerzeichen, Vorlagen, gruben aber nicht tief. Aber diejenigen, die ausgegraben hatten, was im Inneren vor sich ging, wurden sehr nützliche und sehr geforderte Kollegen: Wenn plötzlich etwas nicht mehr ging, gingen alle zu ihnen um Rat und baten um Nuancen und Hilfe beim Debuggen. Es war eine lustige Zeit, weil ich daran interessiert war herauszufinden, was drin ist. So erlangte er bei Kollegen eine billige Popularität.

Neben dem Ökosystem der Abhängigkeiten wird auch mit gemeinsam genutztem Code gearbeitet. Bereits zu Beginn nahm die Anzahl der Projekte explosionsartig zu, und es war erforderlich, mit gemeinsamem Code zu arbeiten, gemeinsame Bibliotheken zu erstellen und so weiter. Wir haben angefangen, eine solche interne Open Source zu machen. Wir haben die allgemeine Funktionalität der Autorisierung, die Arbeit mit Protokollen, mit anderen gängigen Dingen, internen APIs und internen Speichern erstellt. Wir haben das alles in Form von Bibliotheken gemacht und es in das interne Repository gestellt. Zuerst waren dies SVN-Repositorys, dann interner GitHub.
Und am Ende haben sie all diese Abhängigkeiten gepackt, all diese Bibliotheken sind auch in deb, geladen in ein einziges Repository. Daraus wurde eine solche Paketumgebung gebildet. Wenn Sie ein neues Projekt gestartet haben, können Sie mehrere Bibliotheken dort platzieren, eine Funktionsbasis erhalten und das Projekt sofort in der Yandex-Infrastruktur starten. Es war sehr bequem.

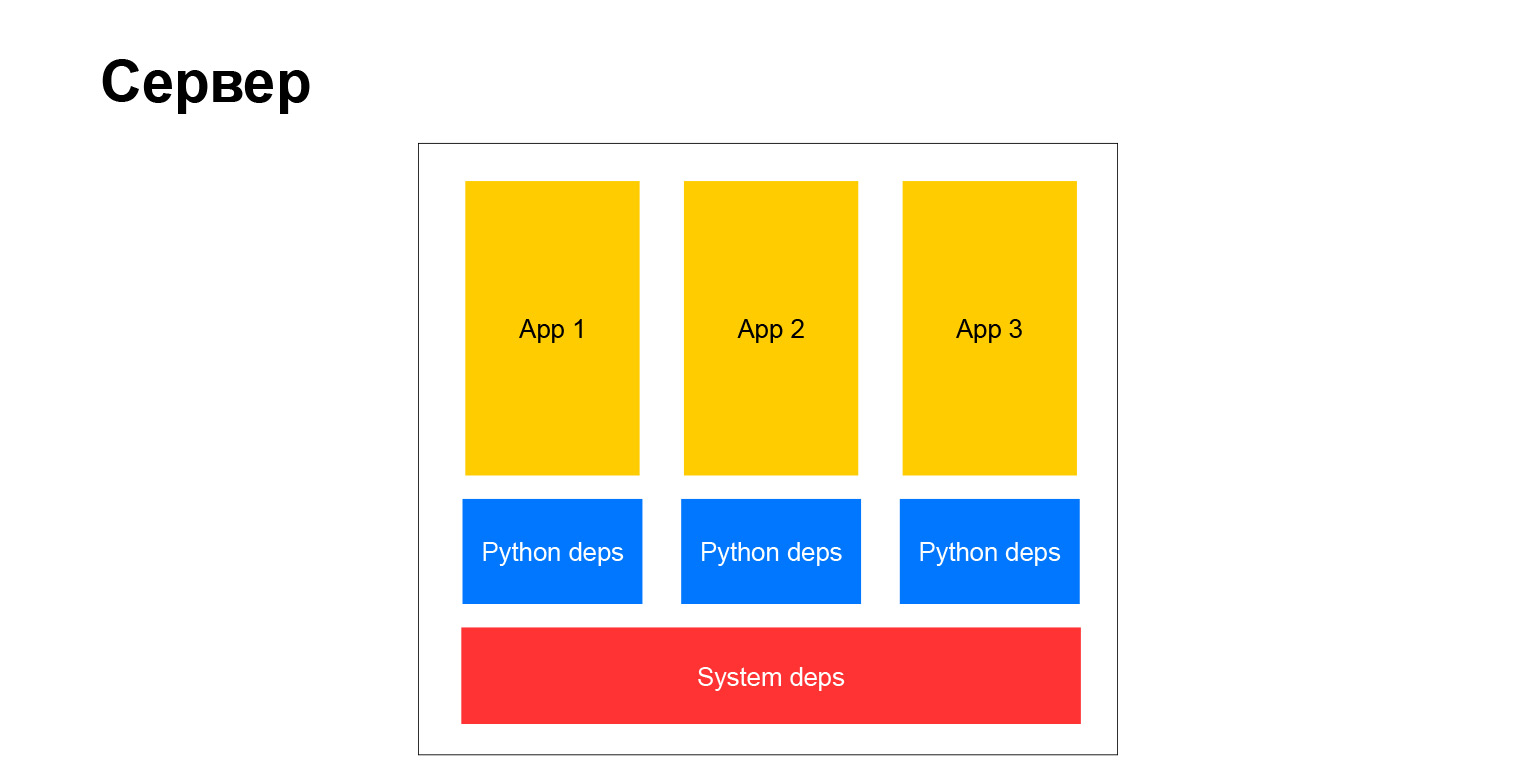
Wie sah unser typischer Server aus? Klassisch. Es gibt Systemabhängigkeiten, es gibt Python-Abhängigkeiten und Anwendungen. Daraus ergeben sich mehrere Dinge. Zunächst müssen alle Anwendungen, die auf demselben Server und daher auf demselben Cluster ausgeführt werden, dieselben Abhängigkeiten aufweisen. Wenn Sie ein Paketsystem installieren, hat es immer dieselbe Version. Es können nicht mehrere vorhanden sein. Sie müssen synchronisieren.
Wenn es nur wenige Projekte gibt, kann es trotzdem irgendwie gemacht werden. Wenn es viel gibt, wird alles sehr kompliziert. Sie werden von verschiedenen Teams hergestellt, es fällt ihnen schwer, sich zu einigen. Jedes Team möchte frühzeitig ein Upgrade auf eine Bibliothek durchführen oder das Framework aktualisieren. Und alle anderen sollten dem folgen. Dies führt im Laufe der Zeit zu vielen Problemen. Dies veranlasste uns, ein solches Schema aufzugeben, um in die nächste Ära überzugehen. Aber ich werde etwas später darüber sprechen.
Lassen Sie uns über die Entwicklungsumgebung sprechen. Aber hier ist ein so erweitertes Verständnis der Entwicklungsumgebung. So kommen Sie zur Arbeit, wie Sie Code schreiben, wie Sie ihn debuggen, wie Sie damit arbeiten, wo Sie ihn überprüfen, wie Sie ihn ausführen, wo Sie Tests ausführen und so weiter.

Als ich zur Firma kam, arbeiteten wir alle an Remote-Entwicklungsservern. Das heißt, Sie haben eine Art Desktop, unter Windows oder Linux spielt es keine Rolle. Sie gehen zu einem Remote-Server mit dem richtigen Debian und dem richtigen Paket-Repository. Und Sie laufen, führen vim, Emacs, schreiben Code, debuggen.
Es ist nicht sehr praktisch, aber dann kannten wir kein anderes Leben. Diejenigen, die das Glück haben, einen Linux-Desktop oder -Laptop zu haben, könnten versuchen, dies lokal zu tun. Aber es gab auch keine besonderen Anweisungen, nichts. So eine wilde Zeit. Spezielle Leute, die zu dieser Zeit auf Windows und Macs lebten und lokal entwickeln wollten, haben eine virtuelle Maschine aufgebaut, in der sich Linux befindet. Sie haben Code in diese virtuelle Maschine geschrieben und ausgeführt. Genauer gesagt, sie haben den Code auf das Hostsystem geschrieben, den Code in der virtuellen Maschine ausgeführt und das Dateisystem dort irgendwie weitergeleitet, sodass alles synchronisiert wurde. Es hat alles ziemlich schlecht funktioniert, aber irgendwie hat es überlebt.
Was sind die Vor- und Nachteile dieser Ära, dieses Entwicklungsansatzes? In der Tat gibt es solide Nachteile:
- Wie gesagt, die allgemeinen Cluster waren eng.
- Alle Projekte im Cluster sollten dieselben Abhängigkeiten haben.
- . , , Django . , . 15-20 . . , , — . X, . , . - , - , . . , , . .
- Yandex war von der Debian-Infrastruktur abhängig. Wir haben es unterstützt, Pakete erstellt und ein internes Repository gepflegt. Und das ist natürlich auch nicht sehr gut, nicht sehr praktisch, nicht sehr flexibel. Sie sind auf seltsame Dinge angewiesen, die nicht für das Unternehmen getan wurden. Debian als Open Source-Lösung, als Linux-Distribution, wurde dennoch für andere Aufgaben entwickelt.
Lassen Sie uns etwas mehr über Django sprechen. Warum haben wir damit angefangen? Ich dachte gerade vor dem Bericht, als ich auf einem Stuhl saß, dass ich vor 11 Jahren in Kiew auf einer Konferenz mit dem gleichen Thema „Warum sollte ich Django verwenden?“ Sprach. Dann hat es mir selbst gefallen. Ich war ein bewunderter Entwickler, der die Dokumentation gelesen und mein erstes Projekt erstellt hat, und es scheint ihm, dass alles, jetzt ist dieses Tool für alles universell und Sie können, ich weiß nicht, sogar Nägel darauf hämmern.
Aber es ist viel Zeit vergangen. Ich liebe Django immer noch, es wird immer noch ziemlich oft in unserer Abteilung und im Unternehmen im Allgemeinen verwendet. Zum Beispiel hatte Alice schon vor dem Herbst 2018 Django im Backend. Jetzt ist sie nicht mehr da, aber um schnell anfangen zu können, haben ihre Kollegen sie ausgewählt. Da einige der Vorteile immer noch gültig sind - ein großes Ökosystem - gibt es immer noch viele Spezialisten. Es gibt alle Batterien, die Sie brauchen.
Und es gibt genug Flexibilität. Wenn Sie gerade erst anfangen, mit Django zu arbeiten, scheint es Ihnen, dass es Sie sehr einschränkt, Sie in die Hand nimmt und einen gewissen Arbeitsfluss erfordert. Wenn Sie jedoch etwas tiefer graben, können viele Dinge deaktiviert, geändert und konfiguriert werden. Und wenn Sie dies geschickt einsetzen, können Sie alle Extras erhalten, die mit dem beliebtesten Python-Framework verbunden sind. Sie können alle Nachteile umgehen. Es gibt auch viele von ihnen, aber sie können auf die eine oder andere Weise gestoppt werden.
Alter 2: Eisen + Venv
Wir haben über diese Ära gesprochen. Das Jahr 2011 ist zu Ende gegangen, wir sind in die nächste Ära eingetreten, "Iron + venv". Sie kennen sich bereits mit Hardware aus, jetzt müssen Sie mitteilen, was passiert ist und woher der Name venv stammt. Lyrischer Exkurs: venv ist nicht entstanden, weil virtuelle Maschinen erschienen sind. Warum in Anführungszeichen? Weil wir angefangen haben, alle möglichen containerähnlichen Dinge wie OpenVZ oder LXC auszuprobieren. Damals waren sie sehr schlecht entwickelt, nicht wie heute. Sie sind nicht wirklich mit uns geflogen. Wir lebten immer noch in gemeinsamen Clustern, wir mussten immer noch zusammen mit anderen Projekten Schulter an Schulter auf denselben Maschinen existieren. Wir suchten nach einer Lösung.

Zum Beispiel haben wir von init zu upstart systemd gewechselt und wenig später Flexibilität beim Starten unserer Anwendungen erhalten. Wir haben FastCGI aufgegeben und entweder die WSGI-Schnittstelle für die Kommunikation mit dem Webserver oder HTTP verwendet. Zu diesem Zeitpunkt verwendeten wir bereits mehr oder weniger modernes Python, das Ökosystem war bereits sehr gut entwickelt. Wir sind als Webserver auf nginx umgestiegen, im Allgemeinen war alles in Ordnung.

Wir haben auch begonnen, neue Rahmenbedingungen für uns selbst anzupassen. Zum Beispiel haben sie angefangen, Tornado zu benutzen. Natürlich war Flask bereits zu diesem Zeitpunkt erschienen, nach 2012 war Flask bereits sehr modisch, beliebt und drohte Django, das Podest populärer Frameworks in Python abzulegen. Und natürlich haben sie angefangen, Sellerie zu verwenden. Denn wenn Projekte wachsen, wächst ihre Anzahl, sie werden stärker ausgelastet, lösen mehr Aufgaben, verarbeiten mehr Daten, und Sie benötigen ein Framework für die Ausführung von Offline-Aufgaben in einem großen Computercluster. Natürlich haben wir dafür angefangen, Sellerie zu verwenden. Aber dazu später mehr.

Was sich dramatisch geändert hat, ist die Funktionsweise von Abhängigkeiten. Wir begannen eine virtuelle Umgebung zu sammeln. Zu dieser Zeit kam die Python-Community zu dem Punkt, dass es nicht möglich ist, Python-Bibliotheken in das System einzufügen, sondern eine virtuelle Umgebung zu erstellen, alle benötigten Python-Abhängigkeiten dort abzulegen, und diese Umgebung ist völlig unabhängig. Auf einer Maschine können sich so viele solche virtuellen Umgebungen befinden. Dies ist Isolation, eine sehr bequeme Sucht. Du benutzt es immer noch. Und wir haben auch alles angepasst. Was haben wir als Ergebnis getan? Wir haben eine virtuelle Umgebung erstellt und alle Python-Abhängigkeiten dort abgelegt, in ein Deb-Paket gepackt und bereits auf den Server übertragen.
Infolgedessen störten sich alle Projekte nicht mehr gegenseitig. Abhängig von der allgemeinen Python-Abhängigkeit im System konnten sie leicht auswählen, welche Version des Frameworks oder der Bibliothek verwendet werden soll. Es ist sehr bequem. Änderungen wurden auch am freigegebenen Code vorgenommen. Da wir die Debian-Infrastruktur teilweise aufgegeben und insbesondere die Installation von Python-Abhängigkeiten mit Deb-Paketen eingestellt haben, brauchten wir etwas, wo wir all unseren gemeinsamen Code und unsere gemeinsamen Bibliotheken entladen und von wo wir sie ablegen konnten.

Link von der Folie
Zu diesem Zeitpunkt gab es bereits mehrere PyPI-Implementierungen, dh ein Repository von Python-Paketen, Implementierungen, die insbesondere in Django geschrieben wurden. Und wir haben einen von ihnen ausgewählt. Es heißt Localshop, hier ist ein Link. Dieses Repository lebt noch, es hat bereits ungefähr tausend interne Pakete. Das heißt, von ungefähr 2011-2012 hat ein Unternehmen von der Größe von Yandex ungefähr tausend verschiedene Bibliotheken generiert, Dienstprogramme, die in Python geschrieben wurden und vermutlich in anderen Projekten wiederverwendet werden. Sie können die Skala schätzen.
Alle Bibliotheken werden in diesem internen Repository veröffentlicht. Und von dort aus werden sie entweder in Python installiert oder es gibt eine spezielle automatische Infrastruktur, die sie in Debian verwandelt. Es ist alles mehr oder weniger automatisiert und bequem. Wir haben aufgehört, so viele Ressourcen für die Wartung der Debian-Infrastruktur zu verschwenden. Es hat alles mehr oder weniger von selbst funktioniert.
Und das ist ein qualitativer Schritt. Hier ist ein Diagramm mit dem, worüber ich gesprochen habe.
Das heißt, Python-Abhängigkeiten sind endlich nicht mehr für alle gleich. Die System-sind noch da, aber nicht viele. Für einen Treiber für eine Datenbank, einen XML-Parser, sind beispielsweise Systembinärdateien erforderlich. Im Allgemeinen konnten wir zu diesem Zeitpunkt diese Abhängigkeiten nicht loswerden.

Die Entwicklungsumgebung hat sich ebenfalls geändert. Da venv, eine virtuelle Umgebung, zu dieser Zeit überall zugänglich wurde und funktionierte, konnten wir unser Projekt im Allgemeinen auf jeder lokalen Plattform zusammenstellen. Dies machte das Leben viel einfacher. Es war nicht mehr nötig, sich mit Debian zu beschäftigen, es wurden keine virtuellen Maschinen benötigt. Sie können einfach ein beliebiges Betriebssystem verwenden, z. B. Virtual Venv, und dann etwas installieren. Und es hat funktioniert.
Was sind die Vorteile dieses Schemas? Da wir mit dieser Konfiguration von Parametern ziemlich lange gelebt haben - vielleicht etwas mehr als drei Jahre -, ist es einfacher geworden, in Cluster-Hostels zu leben. Das ist wirklich praktisch. Das heißt, wir haben aufgehört, abhängig von diesen globalen Updates einiger Django im gesamten Unternehmen zu sein. Wir könnten die für uns geeigneten Versionen genauer auswählen und kritische Abhängigkeiten häufiger aktualisieren, wenn sie Schwachstellen oder etwas anderes beheben. Und es war ein sehr korrekter Weg, es hat uns gefallen und uns viel von allem erspart.
Es gab aber auch Nachteile. Systemabhängigkeiten waren immer noch häufig. Manchmal feuerte es, manchmal störte es. Ich werde noch einmal ein wenig über den Rahmen unserer Abteilung hinausgehen und Ihnen von dem Unternehmen erzählen. Da das Unternehmen groß ist, haben nicht alle mit uns mit diesen Epochen Schritt gehalten. Zu diesem Zeitpunkt verwendete das Unternehmen weiterhin Deb-Pakete, um mit Python-Abhängigkeiten zu arbeiten. Lassen Sie mich Ihnen genauer erklären, warum wir diese oder jene Frameworks verwendet haben. Insbesondere Tornado.

Wir brauchten ein asynchrones Framework, wir haben jetzt Aufgaben dafür. Das dritte Python und sein Asyncio existierten noch nicht oder sie befanden sich in einem Anfangszustand, es war noch nicht sehr zuverlässig, sie zu verwenden. Daher haben wir versucht, das zu verwendende asynchrone Framework auszuwählen. Es gab verschiedene Möglichkeiten: Gevent und Twisted. Höchstwahrscheinlich gab es mehr von ihnen, aber wir haben uns unter ihnen entschieden. Twisted wurde bereits von der Firma verwendet - zum Beispiel wurde das Yandex.Taxi-Backend in Twisted geschrieben. Aber wir haben sie uns angesehen und festgestellt, dass Twisted nicht pythonisch aussieht, selbst PEP-8 entspricht nicht. Und Gevent - es gibt eine Art Hack mit einem Python-Stack im Inneren. Verwenden wir Tornado.
Wir haben es nicht bereut. Wir verwenden Tornado immer noch in einigen Diensten - in denen, die wir noch nicht in Third Python umgeschrieben haben. Das Framework hat im Laufe der Jahre bewiesen, dass es kompakt, zuverlässig und zuverlässig ist.
Und natürlich Sellerie. Ich habe bereits teilweise darüber erzählt. Wir brauchten einen Rahmen für die verteilte Ausführung von zurückgestellten Aufgaben. Wir haben es.

Es war sehr praktisch, dass Sellerie Unterstützung für verschiedene Makler hat. Wir haben dieses b aktiv für verschiedene Aufgaben verwendet, um den einen oder anderen richtigen Broker zu finden. Irgendwo war es Mongo, irgendwo SQS, irgendwo Redis. Aber wir haben versucht, nach Bedarf zu wählen, und es ist uns gelungen.
Trotz der Tatsache, dass es viele Beschwerden über Sellerie gibt, wie es darin geschrieben ist, wie man es debuggt, welche Art von Protokollierung es gibt, funktioniert es eher. Sellerie wird immer noch in fast jedem Projekt in unserer Abteilung und, soweit ich weiß, außerhalb unseres Projekts aktiv verwendet. Sellerie ist ein Muss. Wenn Sie die Ausführung von Aufgaben verzögern müssen, nimmt jeder Sellerie. Oder zuerst nehmen sie es nicht, sie versuchen etwas anderes zu nehmen, aber dann kommen sie immer noch zu Sellerie.
Wir gehen in die nächste Ära. Bereits in der Gegenwart, moderner. Hier spricht der Name der Ära für sich.
Alter 3: Container

Wir haben intern eine Docker-kompatible Cloud. Im Inneren nicht Docker-Laufzeit, sondern interne Entwicklung. Gleichzeitig können Sie dort Docker-Images bereitstellen. Es hat uns sehr geholfen, weil wir das gesamte Docker-Ökosystem für Entwicklung und Test nutzen konnten. Wir könnten alle möglichen Extras verwenden und dann, nachdem wir das getestete Bild erhalten haben, es einfach in diese Cloud hochladen. Es begann dort und funktionierte wie es sollte.
Zu diesem Zeitpunkt waren wir bereits unabhängig davon, welches Betriebssystem sich im Container befand. Sie können jeden wählen. Wir haben natürlich keine gewöhnlichen Dämonen benutzt, sondern zum Beispiel einen Vorgesetzten. Anschließend wechselten alle zu uWSGI - es stellte sich heraus, dass uWSGI nicht nur weiß, wie Sie Ihre Webanwendungen ausführen und eine Schnittstelle für den darin enthaltenen Webserver bereitstellen. Es ist auch nur eine gute generische Sache zum Starten von Prozessen.
Es gibt jedoch eine etwas seltsame Konfiguration, die jedoch im Allgemeinen praktisch ist. Wir haben die unnötige Essenz beseitigt und angefangen, alles über uWSGI zu tun. Wir verwenden es auch, um mit dem Webserver zu kommunizieren. Die Besonderheiten unserer Cloud sind so, dass wir das uWSGI-Protokoll nicht verwenden können, um mit dem Balancer, der global in der Cloud vertreten ist, als Komponente zu kommunizieren. Aber das ist OK. In uWSGI ist der HTTP-Server ziemlich gut implementiert und funktioniert schnell und zuverlässig.

Was ist mit Frameworks? Das Falcon-Framework wurde angezeigt, und wir haben dieselbe Alice mit Django auf Falcon neu geschrieben, da es eine bestimmte Anzahl von Apis gab - es war notwendig, dass sie schnell arbeiteten, aber gleichzeitig waren sie nicht sehr kompliziert.
Django wurde irgendwann ein wenig überflüssig, und um die Geschwindigkeit zu erhöhen und eine so große Abhängigkeit, eine große Bibliothek, loszuwerden, beschlossen wir, sie in Falcon umzuschreiben.
Und natürlich Asyncio. Wir haben begonnen, neue Dienste im dritten Python zu schreiben und die alten im dritten Python neu zu schreiben. Nur in unserer Abteilung gibt es jetzt ungefähr 30 Dienste, die in Python geschrieben sind. Dies sind 30 vollwertige Produkte mit Backend, Frontend und eigener Infrastruktur. Was Daten verarbeitet, bietet Dienstleistungen sowohl für interne als auch für externe Verbraucher.
Wie Sie wissen, verfügt das Unternehmen jedoch über Tausende von Python-Diensten, die sich unterscheiden. Sie befinden sich auf verschiedenen Frameworks, verschiedenen Python, älteren und neueren. Jetzt verwendet das Unternehmen fast alle modernen Frameworks, die Sie kennen. Django, Flask, Falcon, etwas anderes, asynchron - Tornado, Twisted, asyncio. Alles ist gebraucht und nützlich.
Kehren wir zur Struktur der Ära zurück - wie wir angefangen haben, mit Abhängigkeiten zu arbeiten.

Hier ist alles einfach. Jetzt können wir die virtuelle Umgebung nicht verwenden. Wir brauchen keine Deb-Pakete. Zum Zeitpunkt der Erstellung des Images installieren wir einfach alles, was wir mit pip benötigen. Es ist völlig isoliert. Wir stören niemanden. Und sehr praktisch. Bei allen Systemabhängigkeiten können Sie ein beliebiges Basis-Image von Debian, Ubuntu oder was auch immer auswählen. Wir mögen. Volle Freiheit.
Tatsächlich hat die völlige Freiheit, wie Sie wissen, eine zweite Seite. Wenn Sie ein großes Unternehmen haben und vor allem, wenn Sie einheitliche Entwicklungsmethoden und -methoden, Testmethoden und Dokumentationsansätze fördern möchten, sehen Sie sich in diesem Moment damit konfrontiert, dass dieser Zoo einerseits irgendwo hilft. Auf der anderen Seite erschwert es. Er kann beispielsweise nicht einfach eine Bibliothek in alle Dienste einfügen, da die Dienste unterschiedlich sind. Sie haben verschiedene Versionen von Python, Django oder einem anderen Framework. Das macht die Sache komplizierter. Aber am Ende sah ein typischer Server so aus.
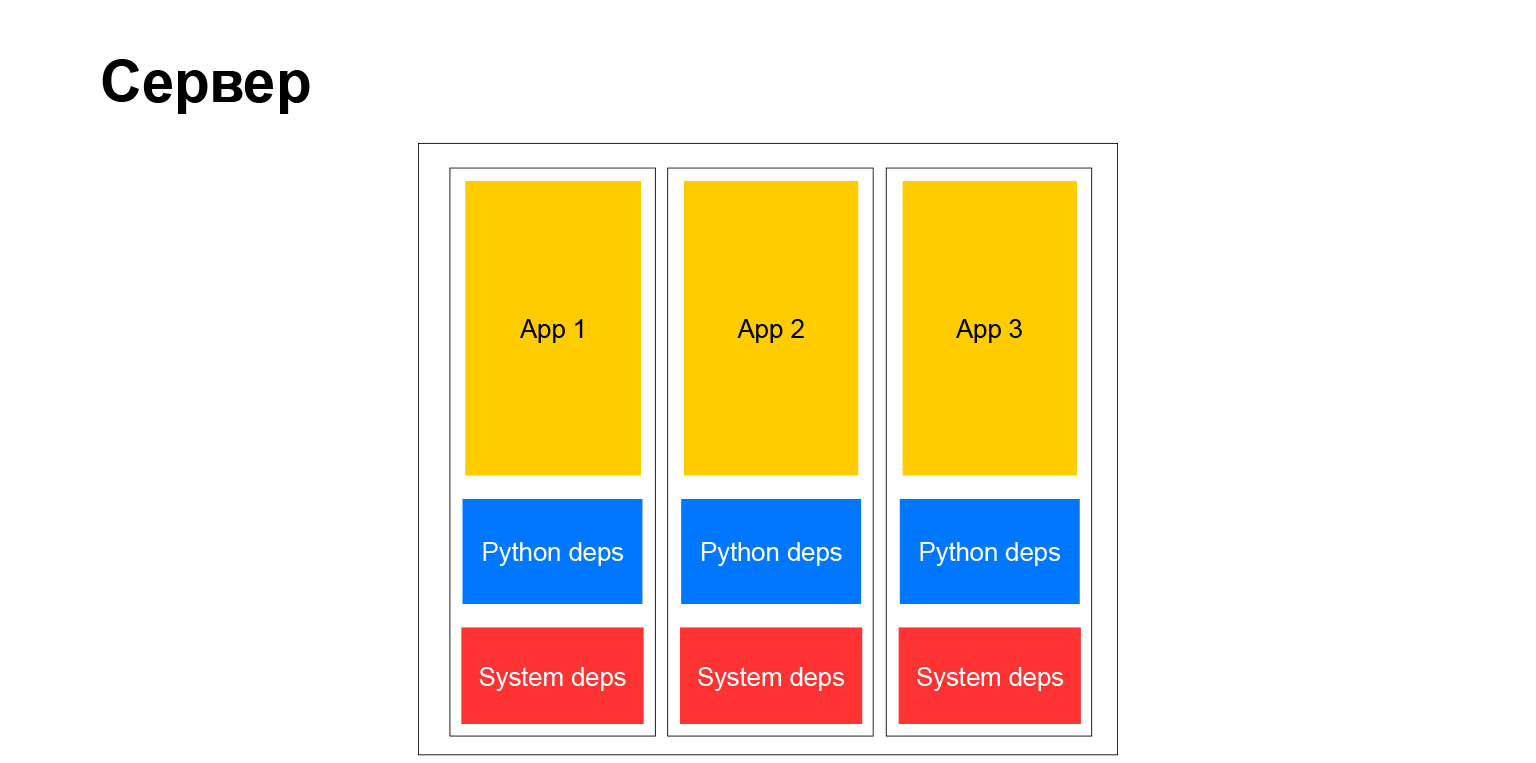
Ja, es ist ein Server. Wir haben völlig unabhängige Container. Jeder von ihnen hat seine eigene Systemumgebung, und unsere Anwendungen drehen sich. Sehr bequem. Aber wie gesagt, es gibt Nachteile.
Kehren wir für einen Moment zum Docker zurück. Wir haben angefangen, Docker für die Entwicklung zu verwenden, es hat uns sehr geholfen.

Docker ist für alle Plattformen verfügbar. Sie können testen, Docker-Compose verwenden, einen Docker-Schwarm ausführen und versuchen, Ihre Produktionsumgebung in kleinen Clustern zu emulieren, um etwas zu testen. Vielleicht Lasttest. Wir haben begonnen, dies aktiv zu nutzen.
Docker ist auch sehr gut in alle Arten von Entwicklungsumgebungen integriert. Zum Beispiel entwickle ich mich in PyCharm, und die meisten meiner Kollegen auch. Es gibt eine integrierte Docker-Unterstützung mit Vor- und Nachteilen, aber im Allgemeinen funktioniert alles.
Es ist sehr bequem geworden, wir haben einen qualitativen Schritt gemacht, und in diesem Stadium sind wir jetzt. Die Entwicklung mit Docker ist praktisch, obwohl unsere Ziel-Cloud, in der wir unsere Anwendungen bereitstellen, keine vollwertige Docker-Laufzeit ist, einige Einschränkungen aufweist. Dies hindert uns jedoch nicht daran, die Docker Engine lokal und für verwandte Aufgaben zu verwenden.
Lassen Sie uns eine Bestandsaufnahme dieser Ära machen. Vorteile - vollständige Isolation, praktische Toolchain für die Entwicklung und, wie gesagt, IDE-Unterstützung.
Es gibt auch Nachteile. Docker ist überall, aber wenn es nicht Linux ist, funktioniert es ein wenig seltsam. Yandex-Entwickler mit einem MacBook installieren Docker für Mac. Und es gibt Funktionen, zum Beispiel, dass IPv6 seltsam funktioniert oder Sie es irgendwie optimieren müssen. Und in unserem Unternehmen ist IPv6 sehr verbreitet. Wir haben lange keine IPv4-Adressen mehr, daher ist die gesamte interne Infrastruktur weitgehend an IPv6 gebunden. Und wenn IPv6 auf Ihrem Laptop oder im Docker, der sich auf dem Laptop befindet, nicht funktioniert, Sie leiden und nichts wirklich tun können, müssen wir es umgehen.

Trotzdem lieben wir Docker sehr. Es ist effizient und hat ein gutes Ökosystem. Die Leute kommen von der Straße zu uns, sagen wir - können Sie andocken? Sie - ja, ich kann. Alles in Ordnung ist. Eine Person kommt und beginnt buchstäblich sofort, nützlich zu sein, da sie sich nicht mit dem Starten und Erstellen eines Projekts, dem Ausführen von Tests, dem Betrachten von Compose oder einer Debug-Ausgabe befassen muss. Der Mensch weiß schon alles. Dies ist ein De-facto-Standard in der Außenwelt. Er erhöht unsere Effizienz, wir können den Benutzern schnell Funktionen bereitstellen und geben kein Geld für die Infrastruktur aus.
Alter 4: binärer Build
Aber wir nähern uns bereits der letzten Ära, in die wir gerade eintreten. Und dann werde ich zum Anfang meines Berichts zurückkehren, als ich sagte: Sie kommen mit Ihren Infrastrukturansätzen zu einem großen Unternehmen. Bei Yandex ist es genauso. Wenn es früher eine Debian-Infrastruktur war, ist es jetzt anders. Das Unternehmen verfügt seit geraumer Zeit über ein einziges monolithisches Repository, in dem der gesamte Code nach und nach gesammelt wird. Um ihn herum befinden sich der Montagemechanismus, der verteilte Testmechanismus, eine Reihe von Werkzeugen und alles, was wir noch nicht verwenden, aber jetzt verwenden. Das heißt, unsere Python-Projekte besuchen auch dieses Repository. Wir versuchen, mit den gleichen Werkzeugen zusammenzukommen. Da diese Tools eines einzelnen Repositorys in erster Linie auf C ++, Java und Go ausgerichtet sind, gibt es dort eine Besonderheit.
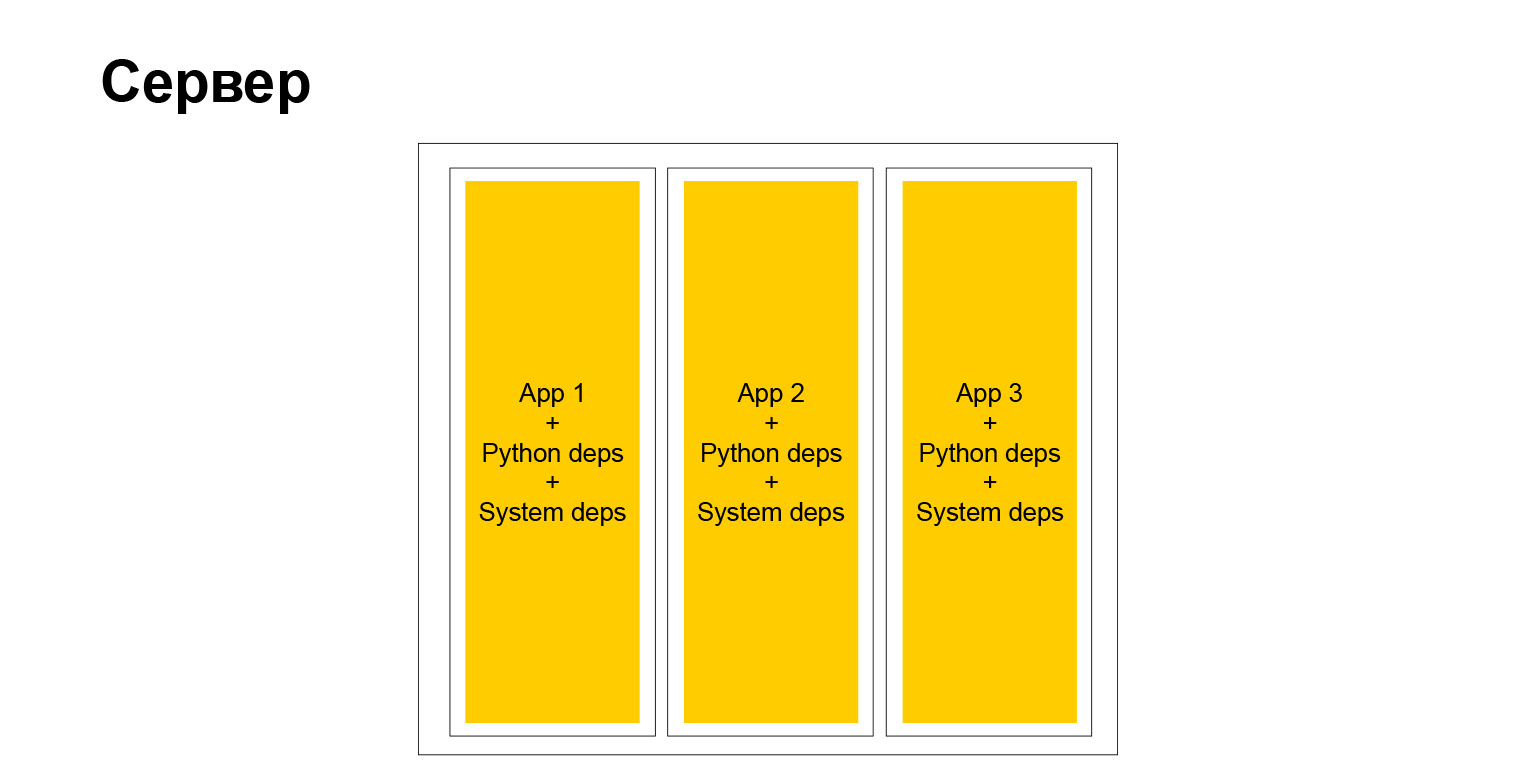
Die Besonderheit ist dies. Wenn das Ergebnis der Erstellung unseres Projekts nun die Docker Engine ist, in der sich unser Quellcode mit allen Abhängigkeiten einfach befindet, kommen wir zu dem Schluss, dass das Ergebnis der Erstellung unseres Projekts nur eine Binärdatei ist. Es ist nur eine Binärdatei, in der es einen Python-Interpreter, Code und unseren Python gibt. Alle anderen erforderlichen Abhängigkeiten sind statisch verknüpft.
Es wird angenommen, dass Sie kommen können, dieses Binär auf jeden Linux-Dienst mit einer kompatiblen Architektur werfen und es wird funktionieren. Und das ist die Wahrheit.
Es scheint ein bisschen unnatürlich. Die meisten Leute in der Python-Community tun das nicht, und ich bin sicher, dass Sie das nicht tun. Das hat Vor- und Nachteile. Vorteile:
- . , , , , , . , . , , . .
- , , , . , , . , . , checkout , , . .
- , .
Und natürlich gibt es ein Minus: ein geschlossenes Ökosystem. Eine Person von außen muss in die Funktionsweise eingetaucht sein, um zu sagen, wie es funktioniert. Er muss es versuchen und wird erst dann wirksam. Wir stehen erst am Anfang dieses Weges. Wenn ich in ein oder zwei Jahren zu dieser Konferenz komme, kann ich Ihnen vielleicht sagen, wie wir diese Transformation durchlaufen haben. Aber jetzt blicken wir optimistisch in die Zukunft und halten uns an einige interne Unternehmensregeln, und es gefällt uns eher als nicht, weil wir viele interne Extras erhalten werden.
Schlussfolgerungen
Sie sind philosophischer. Der Bericht selbst ist weniger technisch als philosophisch.
- Evolution ist unvermeidlich. Wenn Sie einen Dienst erbringen und dieser lange lebt, werden Sie ihn weiterentwickeln, seine Infrastruktur weiterentwickeln und die Art und Weise, wie Sie ihn entwickeln.
- . , , , .
- . , Django, . , . , , , Django - , . , .
- Python-. , , -. , , . , , , , , : , . , .
Das Thema ist sehr groß. Ich habe Ihnen sehr kurz erzählt, wie und was wir tun, wie sich Python in unserem Land entwickelt hat. Sie können jede Epoche nehmen, jeden Gegenstand auf der Folie nehmen und ihn tiefer zerlegen. Und das reicht auch für 40 Minuten - Sie können sehr lange über Abhängigkeiten, über internes Open Source und über Infrastruktur sprechen. Ich gab ein Übersichtsbild. Wenn ein Thema sehr beliebt ist, kann ich es bei den nächsten Meetings oder Konferenzen offenlegen. Vielen Dank.