
Einführung
Die asynchrone Programmierung ist eine Form der parallelen Programmierung, bei der eine Arbeitseinheit getrennt vom Hauptthread der Anwendung ausgeführt werden kann. Wenn die Arbeit endet, wird der Hauptthread benachrichtigt, dass der Workflow beendet wurde oder ein Fehler aufgetreten ist. Dieser Ansatz bietet viele Vorteile, z. B. eine verbesserte Anwendungsleistung und eine höhere Antwortgeschwindigkeit.
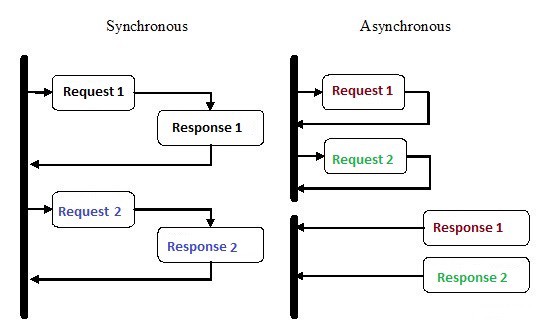
Die asynchrone Programmierung hat in den letzten Jahren aus gutem Grund viel Aufmerksamkeit erhalten. Diese Art der Programmierung kann zwar komplexer sein als die herkömmliche sequentielle Ausführung, ist jedoch wesentlich effizienter.
Anstatt beispielsweise auf den Abschluss der HTTP-Anforderung zu warten , bevor Sie mit der Ausführung fortfahren, können Sie die Anforderung senden und andere in der Schlange stehende Arbeiten mithilfe asynchroner Coroutinen in Python ausführen.
Asynchronität ist einer der Hauptgründe für die Auswahl von Node.js zur Implementierung des Backends. Ein Großteil des Codes, den wir schreiben, insbesondere in E / A-Anwendungen wie Websites, hängt von externen Ressourcen ab. Es kann alles enthalten, von einem entfernten Datenbankaufruf über POST-Anforderungen an einen REST-Service. Sobald Sie eine Anfrage an eine dieser Ressourcen senden, wartet Ihr Code nur auf eine Antwort. Bei der asynchronen Programmierung lassen Sie Ihren Code andere Aufgaben erledigen, während Sie auf eine Antwort von Ressourcen warten.
Wie schafft es Python, mehrere Dinge gleichzeitig zu tun?

1. Mehrere Prozesse
Der naheliegendste Weg ist die Verwendung mehrerer Prozesse. Vom Terminal aus können Sie Ihr Skript zwei-, drei-, vier- und zehnmal ausführen, und alle Skripte werden unabhängig und gleichzeitig ausgeführt. Das Betriebssystem kümmert sich um die Verteilung der Prozessorressourcen auf alle Instanzen. Alternativ können Sie die Multiprozessor- Bibliothek verwenden , die mehrere Prozesse erzeugen kann, wie im folgenden Beispiel gezeigt.
from multiprocessing import Process
def print_func(continent='Asia'):
print('The name of continent is : ', continent)
if __name__ == "__main__": # confirms that the code is under main function
names = ['America', 'Europe', 'Africa']
procs = []
proc = Process(target=print_func) # instantiating without any argument
procs.append(proc)
proc.start()
# instantiating process with arguments
for name in names:
# print(name)
proc = Process(target=print_func, args=(name,))
procs.append(proc)
proc.start()
# complete the processes
for proc in procs:
proc.join()Ausgabe:
The name of continent is : Asia
The name of continent is : America
The name of continent is : Europe
The name of continent is : Africa2. Mehrere Threads
Eine andere Möglichkeit, mehrere Jobs parallel auszuführen, ist die Verwendung von Threads. Ein Thread ist eine Ausführungswarteschlange, die einem Prozess sehr ähnlich ist. Sie können jedoch mehrere Threads in einem einzigen Prozess haben, und alle teilen sich Ressourcen. Dies macht es jedoch schwierig, Stream-Code zu schreiben. Ebenso wird das Betriebssystem die ganze harte Arbeit des Zuweisens von Prozessorspeicher erledigen, aber die globale Interpretersperre (GIL) lässt immer nur einen Python-Thread gleichzeitig laufen, selbst wenn Sie Multithread-Code haben. Auf diese Weise verhindert die GIL unter CPython die Mehrkern-Parallelität. Das heißt, Sie können zwangsweise nur auf einem Kern ausgeführt werden, selbst wenn Sie zwei, vier oder mehr haben.
import threading
def print_cube(num):
"""
function to print cube of given num
"""
print("Cube: {}".format(num * num * num))
def print_square(num):
"""
function to print square of given num
"""
print("Square: {}".format(num * num))
if __name__ == "__main__":
# creating thread
t1 = threading.Thread(target=print_square, args=(10,))
t2 = threading.Thread(target=print_cube, args=(10,))
# starting thread 1
t1.start()
# starting thread 2
t2.start()
# wait until thread 1 is completely executed
t1.join()
# wait until thread 2 is completely executed
t2.join()
# both threads completely executed
print("Done!")Ausgabe:
Square: 100
Cube: 1000
Done!3. Coroutinen und
yield:
Koroutinen sind eine Verallgemeinerung von Unterprogrammen. Sie werden für kooperatives Multitasking verwendet, wenn ein Prozess control (
yield) freiwillig in einer bestimmten Häufigkeit oder während Wartezeiten aufgibt, damit mehrere Anwendungen gleichzeitig ausgeführt werden können. Coroutinen ähneln Generatoren , enthalten jedoch zusätzliche Methoden und geringfügige Änderungen in der Verwendung der Yield-Anweisung . Generatoren erzeugen Daten für die Iteration, während Coroutinen auch Daten verbrauchen können.
def print_name(prefix):
print("Searching prefix:{}".format(prefix))
try :
while True:
# yeild used to create coroutine
name = (yield)
if prefix in name:
print(name)
except GeneratorExit:
print("Closing coroutine!!")
corou = print_name("Dear")
corou.__next__()
corou.send("James")
corou.send("Dear James")
corou.close()Ausgabe:
Searching prefix:Dear
Dear James
Closing coroutine!!4. Asynchrone Programmierung
Die vierte Methode ist die asynchrone Programmierung, an der das Betriebssystem nicht beteiligt ist. Auf der Betriebssystemseite bleibt nur ein Prozess mit nur einem Thread übrig, Sie können jedoch weiterhin mehrere Aufgaben gleichzeitig ausführen. Also, was ist der Trick hier?
Antwort:
asyncio
Asyncio- Das in Python 3.4 eingeführte asynchrone Programmiermodul. Es wurde entwickelt, um Coroutine und Future zu verwenden, um das Schreiben von asynchronem Code zu vereinfachen, und macht es aufgrund fehlender Rückrufe fast so lesbar wie synchronen Code.
Asyncioverwendet verschiedene Konstruktionen:, event loopCoroutinen und future.
- event loop . .
- ( ) – , Python, await event loop. event loop. Tasks, Future.
- Future , . exception.
Mithilfe dieser Funktion können
asyncioSie Ihren Code so strukturieren, dass Unteraufgaben als Coroutinen definiert werden , und Sie können festlegen, dass sie nach Belieben ausgeführt werden, auch zur gleichen Zeit. Coroutinen enthalten Punkte, yieldan denen wir mögliche Kontextwechselpunkte definieren. Wenn sich Aufgaben in der Warteschlange befinden, wird der Kontext gewechselt, andernfalls nicht.
Ein Kontextwechsel
asyncioist event loop, der den Kontrollfluss von einer Coroutine zur anderen überträgt.
Im folgenden Beispiel führen wir 3 asynchrone Aufgaben aus, die einzeln Anforderungen an Reddit stellen, JSON-Inhalte abrufen und ausgeben. Wir verwenden aiohttp - Eine http-Client-Bibliothek, die sicherstellt, dass auch eine HTTP-Anforderung asynchron gestellt wird.
import signal
import sys
import asyncio
import aiohttp
import json
loop = asyncio.get_event_loop()
client = aiohttp.ClientSession(loop=loop)
async def get_json(client, url):
async with client.get(url) as response:
assert response.status == 200
return await response.read()
async def get_reddit_top(subreddit, client):
data1 = await get_json(client, 'https://www.reddit.com/r/' + subreddit + '/top.json?sort=top&t=day&limit=5')
j = json.loads(data1.decode('utf-8'))
for i in j['data']['children']:
score = i['data']['score']
title = i['data']['title']
link = i['data']['url']
print(str(score) + ': ' + title + ' (' + link + ')')
print('DONE:', subreddit + '\n')
def signal_handler(signal, frame):
loop.stop()
client.close()
sys.exit(0)
signal.signal(signal.SIGINT, signal_handler)
asyncio.ensure_future(get_reddit_top('python', client))
asyncio.ensure_future(get_reddit_top('programming', client))
asyncio.ensure_future(get_reddit_top('compsci', client))
loop.run_forever()Ausgabe:
50: Undershoot: Parsing theory in 1965 (http://jeffreykegler.github.io/Ocean-of-Awareness-blog/individual/2018/07/knuth_1965_2.html)
12: Question about best-prefix/failure function/primal match table in kmp algorithm (https://www.reddit.com/r/compsci/comments/8xd3m2/question_about_bestprefixfailure_functionprimal/)
1: Question regarding calculating the probability of failure of a RAID system (https://www.reddit.com/r/compsci/comments/8xbkk2/question_regarding_calculating_the_probability_of/)
DONE: compsci
336: /r/thanosdidnothingwrong -- banning people with python (https://clips.twitch.tv/AstutePluckyCocoaLitty)
175: PythonRobotics: Python sample codes for robotics algorithms (https://atsushisakai.github.io/PythonRobotics/)
23: Python and Flask Tutorial in VS Code (https://code.visualstudio.com/docs/python/tutorial-flask)
17: Started a new blog on Celery - what would you like to read about? (https://www.python-celery.com)
14: A Simple Anomaly Detection Algorithm in Python (https://medium.com/@mathmare_/pyng-a-simple-anomaly-detection-algorithm-2f355d7dc054)
DONE: python
1360: git bundle (https://dev.to/gabeguz/git-bundle-2l5o)
1191: Which hashing algorithm is best for uniqueness and speed? Ian Boyd's answer (top voted) is one of the best comments I've seen on Stackexchange. (https://softwareengineering.stackexchange.com/questions/49550/which-hashing-algorithm-is-best-for-uniqueness-and-speed)
430: ARM launches “Facts” campaign against RISC-V (https://riscv-basics.com/)
244: Choice of search engine on Android nuked by “Anonymous Coward” (2009) (https://android.googlesource.com/platform/packages/apps/GlobalSearch/+/592150ac00086400415afe936d96f04d3be3ba0c)
209: Exploiting freely accessible WhatsApp data or “Why does WhatsApp web know my phone’s battery level?” (https://medium.com/@juan_cortes/exploiting-freely-accessible-whatsapp-data-or-why-does-whatsapp-know-my-battery-level-ddac224041b4)
DONE: programmingVerwenden von Redis und Redis Queue RQ
Die Verwendung von
asynciound ist aiohttpnicht immer eine gute Idee, insbesondere wenn Sie ältere Versionen von Python verwenden. Darüber hinaus müssen Sie manchmal Aufgaben auf verschiedene Server verteilen. In diesem Fall können Sie RQ (Redis Queue) verwenden. Dies ist eine gängige Python-Bibliothek zum Hinzufügen von Jobs zu einer Warteschlange und zum Verarbeiten von Jobs durch Mitarbeiter im Hintergrund. Zum Organisieren der Warteschlange wird Redis verwendet - eine Datenbank mit Schlüsseln / Werten.
Im folgenden Beispiel haben wir der Warteschlange
count_words_at_urlmithilfe von Redis eine einfache Funktion hinzugefügt .
from mymodule import count_words_at_url
from redis import Redis
from rq import Queue
q = Queue(connection=Redis())
job = q.enqueue(count_words_at_url, 'http://nvie.com')
******mymodule.py******
import requests
def count_words_at_url(url):
"""Just an example function that's called async."""
resp = requests.get(url)
print( len(resp.text.split()))
return( len(resp.text.split()))Ausgabe:
15:10:45 RQ worker 'rq:worker:EMPID18030.9865' started, version 0.11.0
15:10:45 *** Listening on default...
15:10:45 Cleaning registries for queue: default
15:10:50 default: mymodule.count_words_at_url('http://nvie.com') (a2b7451e-731f-4f31-9232-2b7e3549051f)
322
15:10:51 default: Job OK (a2b7451e-731f-4f31-9232-2b7e3549051f)
15:10:51 Result is kept for 500 secondsFazit
Nehmen Sie als Beispiel eine Schachausstellung, in der einer der besten Schachspieler mit einer großen Anzahl von Menschen konkurriert. Wir haben 24 Spiele und 24 Leute, mit denen wir spielen können. Wenn ein Schachspieler synchron mit ihnen spielt, dauert es mindestens 12 Stunden (vorausgesetzt, ein durchschnittliches Spiel dauert 30 Züge, denkt der Schachspieler innerhalb von 5 Sekunden über einen Zug nach und Gegner - ca. 55 Sekunden.) Im asynchronen Modus kann der Schachspieler jedoch einen Zug ausführen und dem Gegner Zeit zum Nachdenken lassen. In der Zwischenzeit wechselt er zum nächsten Gegner und teilt den Zug. So können Sie in 2 Minuten in allen 24 Spielen einen Zug machen und alle in nur einer Stunde gewinnen.
Dies ist gemeint, wenn sie sagen, dass Asynchronität die Arbeit beschleunigt. Wir sprechen von einer solchen Geschwindigkeit. Ein guter Schachspieler beginnt nicht schneller Schach zu spielen, nur die Zeit ist optimierter und es wird nicht mit Warten verschwendet. So funktioniert es.
Nach dieser Analogie wird der Schachspieler ein Prozessor sein, und die Hauptidee wird darin bestehen, den Prozessor so wenig wie möglich im Leerlauf zu halten. Es geht darum, immer etwas zu tun zu haben.
In der Praxis wird Asynchronität als eine Art der parallelen Programmierung definiert, bei der einige Aufgaben den Prozessor während Wartezeiten freigeben, damit andere Aufgaben davon profitieren können. Es gibt verschiedene Möglichkeiten, um in Python eine Parallelität zu erreichen, die Ihren Anforderungen, dem Codefluss, der Datenverarbeitung, der Architektur und den Anwendungsfällen entspricht, und Sie können eine davon auswählen.
.